dl034: jahresrückblick 2022
Hier ist unser traditioneller Jahresrückblick – wir gucken uns das Jahr 2022 nochmal an. Den Anfang machen wir mit einem kleinen Schnelldurchlauf durch das Jahr. Dann gucken wir einmal auf datenleben selbst, weil unser Podcast produziert Daten und die gucken wir uns an. Gibt es da vielleicht irgendetwas, was wir 2022 beobachtet haben? Was waren unsere Lieblingsfolgen? Im Zentrum steht für uns aber die Frage, was wir so aus 2022 mitnehmen an Themen und Erkenntnissen. Eine Sache hat dabei besonders viel hergegeben, das Thema Machine Learning in 2022. Stichworte sind Bildgenerierung, chatGPT können wir natürlich nicht auslassen. Und zum Abschluss versuchen wir uns wieder an einem kleinen Ausblick, was dieses Jahr auf uns zukommt.
Links und Quellen
- Twitter: @datenleben
- Mastodon: @datenleben@podcasts.social
- Webseite: www.datenleben.de
- Mastodon.social, AnitaWorks9698: "Worauf ich bei der Genforschung noch hinweisen möchte, ..."
- Twitter, Kelly_McKernan: "This is what I mean by uncanny valley."
- gofundme: Protecting Artists From AI Technologies
- futurezone: Rätselhafte, gruselige Frau taucht immer wieder in KI-Bildern auf
- GitHub, Facebook Research: demucs
- YouTube, Kevin MacLeod: Happy Happy Game Show
- https://www.riffusion.com/about
- sweetcocoa.github.io: Pop2Piano : Pop Audio-Based Piano Cover Generation
- GitHub, OpenAI: Whisper
- Cory Doctorow: Undetectable backdoors for machine learning models
- science.org, Robert F. Service: Dreaming up new proteins, AI churns out possible medicines and vaccines
- ECMWF.int: ECMWF open data: real-time
- GitHub, ecmwf: ecmwf-opendata
- bydata.github.io: Recreating the New York Times COVID-19 Spiral Graph
- Butler Univeristy: A New Look at the Jotto Problem
- https://joinbookwyrm.com/instances/
- YouTube, datenleben: Können Computer malen?
Schlagworte zur Folge
Maschinelles Lernen, Neuronale Netze, Bildgenerierung, ChatGPT, Offene Daten, Datenvisualisierung
Intro (00:00:00)
Thema des Podcasts (00:00:18)
Helena: Willkommen zu unserer 34. Folge beim datenleben-Podcast, dem Podcast über Data Science. Wir sind Helena
Janine: und Janine
Helena: und möchten mit euch die Welt der Daten erkunden. Es wird immer wichtiger, Daten in das große Ganze einordnen zu können. Wer schon immer mehr über Daten und deren Effekt auf unser Leben wissen wollte, ist hier genau richtig.
Thema der Folge (00:00:38)
Janine: Ja, und damit willkommen im Jahr 2023, das wir damit eröffnen, dass wir traditionellerweise einen Rückblick machen, was wir einmal so beschlossen haben, als wir anfingen. Und ja, jetzt ist es der dritte Jahresrückblick und wir gucken uns das Jahr 2022 nochmal an. Den Anfang machen wir auf jeden Fall damit, dass wir wie die letzten beiden Male auch einen kleinen Schnelldurchlauf durch das Jahr machen und ein paar Ereignisse herausgepickt haben, die als kleine Chronik durchgegangen werden. Wie immer war die Historie in Wikipedia sehr hilfreich dabei, Ereignisse auszusuchen. Dann gucken wir einmal auf datenleben selbst, weil unser Podcast produziert Daten und die gucken wir uns an, was war 2022 so, gibt es da vielleicht irgendetwas, was wir beobachtet haben? Was waren unsere Lieblingsfolgen? Und dann kommen wir zum Kernpunkt und gucken uns an, was wir so aus 2022 mitnehmen, nämlich Themen und Erkenntnisse, und ihr werdet sehr schnell feststellen, das wird dieses Mal, naja, monothematisch ist zu viel gesagt, weil das Thema ist extrem breit gefächert und es gibt da eine große Varianz an Sachen, die man besprechen kann, aber im Wesentlichen reden wir viel über Machine Learning, weil 2022 irgendwie das Machine Learning-Jahr war. Also so Stichworte sind Bildgenerierung, chatGPT können wir natürlich nicht auslassen. Ja, und dann gucken wir vielleicht doch nochmal ein bisschen, was sonst noch so an Themen angefallen ist, so im Data-Science-Bereich. Und ja, dann vielleicht noch ein kleiner Ausblick, was uns wohl in diesem Jahr so erwarten könnte, also sowohl für den Podcast als auch etwas allgemeiner.
Warum ist das Thema interessant? (00:02:32)
Helena: Genau, und wir machen diesen Jahresrückblick, weil uns das interessiert und weil es gleichzeitig auch eine gute Möglichkeit ist, nochmal Ergänzungen zu alten Folgen aufzunehmen und ein bisschen auch mal meta über den Podcast zu reden, weil wir dann auch über Themen nochmal reden können, für die wir jetzt keine ganze Folge eingeplant haben.
Janine: Ja, wobei, eines dieser Themen ist ja ein Thema, von dem wir auch dachten, es wird keine ganze Folge und dann ist es eine ganze Folge geworden und wir können trotzdem noch etwas nachtragen jetzt.
Helena: Genau.
Janine: Ja, der Rückblick.
Einspieler: Jahresrückblick — 2022 im Schnelldurchlauf (00:03:10)
Janine : Jahresrückblick – 2022 im Schnelldurchlauf
* 05. Januar: Bundesregierung beruft Sven Lehmann in das neu geschaffenes Amt des Beauftragten für die Akzeptanz sexueller und geschlechtlicher Vielfalt
* 15. Januar: Der Hunga Tonga Vulkan bricht aus, die erzeugte Druckwelle reist mehrmals um die gesamte Erde und der Ausbruch wird später zu einer der Stärksten jemals gemessenen Erruptionen erklärt.
* 21. Februar: Der Präsident Russlands, Wladimir Putin, erklärt, die im Osten der Ukraine gelegenen Separatistengebiete Donezk und Luhansk als eigenständige Staaten anzuerkennen.
* 24. Februar: Nur drei Tage nach Putins Erklärung, marschiert Russland mit einem Großangriff in der Ukraine ein.
* 27. Februar: In einer Sondersitzung des Deutschen Bundestages werden weitreichende Kursänderung im Angesicht des Krieges in der Ukraine beschlossen, die die Finanzierung der Bundeswehr, Waffenlieferungen an die Ukraine und den Energiesektor betreffen.
* 05. März: Das Wrack der Endurance wurde gefunden. Es ist eines der beiden Schiffe von Ernest Shackletons Antarktis-Expedition, das im November 1915 im Packeis des Weddelmeeres gesunken war.
* 09. März: Im Bundeskabinett wird die Abschaffung des Paragrafen 219a im Strafgesetzbuch beschlossen, der Werbung für Abbruch der Schwangerschaft verboten hat.
* 04. April: Der dritte – und damit letzte – Teil des sechsten Sachstandsberichts des Weltklimarates wird veröffentlicht.
* 04. Mai: Nationaler Erdüberlastungstag 2022. Das ist der Tag, an dem Deutschland so viele Ressourcen verbraucht hat, wie für das Jahr zur Verfügung gestanden hätten.
* 14. Mai: Indien stobbt seine Weizenexporte aufgrund einer durch die seit März anhaltenden Hitzewelle in Südasien verursachten unsicheren Ernährungslage.
* 18. Mai: Die Weltorganisation für Meteorologie (WMO) veröffentlicht ihren Klimazustandsbericht für 2021. Darin stellen sie unter anderem fest, dass die globale Durchschnittstemperatur 2021 etwa 1,1 Grad Celsius über dem vorindustriellen Niveau lag.
* 01. Juni: In Deutschland tritt für die nächsten drei Monate das 9-Euro-Ticket tritt in Kraft.
* 28. Juni: Ein Ehemaliger Wachmann des KZ Sachsenhausen wird zu 5 Jahren Haft verurteilt für 3.500 Fälle wegen Beihilfe zum Mord.
* 08. Juli: Shinzō Abe, ehemalige Premierminister Japans, wird bei einem Wahlkampfauftritt ermordet
* 11. Juli: Die erste Deep Field Aufnahme des James-Webb-Weltraumteleskops wurde veröffentlicht und zeigt einen Abschnitt, den bereits das Hubble Weltraumteleskop abeglichtet hatte. Der Vergleich macht die technische Entwicklung deutlich.
* 18. Juli: Seit diesem Tag ist Werbung für den Abbruch einer Schwangerschaft in der Bundesrepublik Deutschland kein Straftatbestand mehr.
* 12. August: In der Oder kommt es flussaufwärts ab Breslau zu einer Umweltkatastrophe, bei der zahlreiche Fische und andere Lebewesen sterben.
* 30. August: Der Politiker Michail Gorbatschow ist gestorben.
* 31. August: Der UNHCHR in Genf sagt, dass die Anhaltspunkte für Verbrechen gegen die Menschlichkeit durch Verfolgung und Umerziehung der Uiguren in Xinjiang gegeben sind.
* 06. September: Nach Boris Johnsons Rücktritt, wird Liz Truss zur Premierministerin des Vereinigten Königreichs ernannt.
* 08. September: Queen Elisabeth II. stirbt nach siebzigjähriger Regentschaft, ihr Sohn Charles III. wird zwei Tage später zum neuen König von Großbritannien und Nordirland sowie Oberhaupt des Commonwealth of Nations proklamiert.
* 19. September: Der ukrainische Präsident Selenskyj erhebt vor den Vereinten Nationen Klage gegen die russische Offensive auf die Ukraine.
* 20. September: Die anlasslose Vorratsdatenspeicherung wird vom Europäischen Gerichtshof für rechtswidrig erklärt.
* 08. Oktober: Die Deutsche Bahn versinkt im Chaos, mal wieder, aber diesmal weil Menschen zwei wichtige Kabel durchtrennt haben und das Zugfunknetz großflächig ausgefallen ist. 3 Stunden keine Fahrten, nichtmal unpünktliche.
* 11. Oktober: Die NASA bestätigt, dass die DART Mission – der geplante Einschlag eines Raumfahrtobjektes auf der Oberfläche eines Asteroiden – erfolgreich war. Damit sollen Erkenntnisse über die Abwehr von Asteroiden gewonnen werden, die der Erde zu nahe kommen könnten.
* 15. Oktober: Bei anhaltenden Protesten im Iran gegen gegen die autoritäre Regierung und Polizeigewalt kommt es während der Proteste zu einem großen Brand im Evin-Gefängnis, wo hauptsächlich politische Gefangene inhaftiert sind. Mehrere Menschen starben, viele wurden verletzt.
* 20. Oktober: Nach nur 45 Tagen Amtszeit, tritt die britische Premierministerin Liz Truss zurück.
* 29. Oktober: Bei Halloween-Feierlichkeiten bricht in der Nacht auf den 30. Oktober in der südkoreanischen Stadt Seoul eine Massenpanik im dichten Gedränge von Menschen aus. Viele sterben oder werden verletzt.
* 06. November: In Ägypten beginnt die 27. UN-Klimakonferenz
* 10. November: Die Deutsche Bundestag beschließt wegen Unregelmäßigkeiten bei der Wahldurchführung der Bundestagswahl vom 26. September 2021 die Wahlwiederholung in 431 Berliner Wahlbezirken.
* 15. November: Der Bevölkerungsfond der Vereinten Nationen gibt bekannt, dass die Acht-Milliarden-Menschen-Marke überschritten wurde. Die Festlegung auf den 15. November ist symbolisch zu verstehen, da die Schätzung der Weltbevölkerung eine Unsicherheit von +/- 5% enthält.
* 27. November: Einer der größten aktiven Vulkane der Erde bricht nach 38 Jahren wieder aus und zwar der Mauna Loa auf Hawaii.
* 07. Dezember: 25 Menschen aus der Reichsbürgerbewegung wurden bei einer umfangreichen Razzia wegen des Verdachtes eines geplanten Staatsstreiches und Verdacht auf Bildung einer terroristischen Vereinigung verhaftet.
* 08. Dezember: In Brüssel wird sich auf die Aufnahme Kroatiens in den Schengen-Raum zum 01. Januar 2023 geeinigt. Über Bulgarien und Rumänien konnte allerdings keine Einigung erzielt werden.
* 09. Dezember: Eine der Vizepräsidentinnen des Europäischen Parlaments, Eva Kaili, wird wegen Korruptionsverdachtes festgenommen.
* 29. Dezember: Die Deutsche Post gibt bekannt, dass zum Jahresende der Dienst eingestellt wird, Telegramme verschicken zu können.
Wie sehen die datenleben-daten für 2022 aus? (00:09:10)
Helena: Ja, datenleben ist jetzt seit zweieinhalb Jahren auf Sendung und was das jetzt für die datenleben-Daten für 2022 bedeutet, ist, ja, wir sind ganz zufrieden, weil wir immer mehr Leute erreichen und die Zahlen vor sich hin wachsen. Das heißt, ja, im Vergleich zum Jahr davor gab es einen stetigen Anstieg von Downloadzahlen. Wenn man jetzt von einem linearen Wachstum ausgeht, dann können wir auch davon ausgehen, dass es, also es sieht gerade sehr linear aus, wenn man sich das auf eine bestimmte Art und Weise anguckt, von daher gehen wir davon aus, dass auch 2023 wieder mehr Leute dazukommen werden, was uns sehr freut. Wenn man jetzt allerdings nicht die absoluten Zahlen, sondern die relativen Zahlen pro Tag sich anguckt, sieht es nicht ganz so linear aus, sondern das könnte dann auch schon eher ein bisschen exponentieller sein, aber mit, ja, gemäßigten Anstieg. Aber auch da erwarten wir natürlich, dass es mehr wird. Mal schauen, wie es wird.
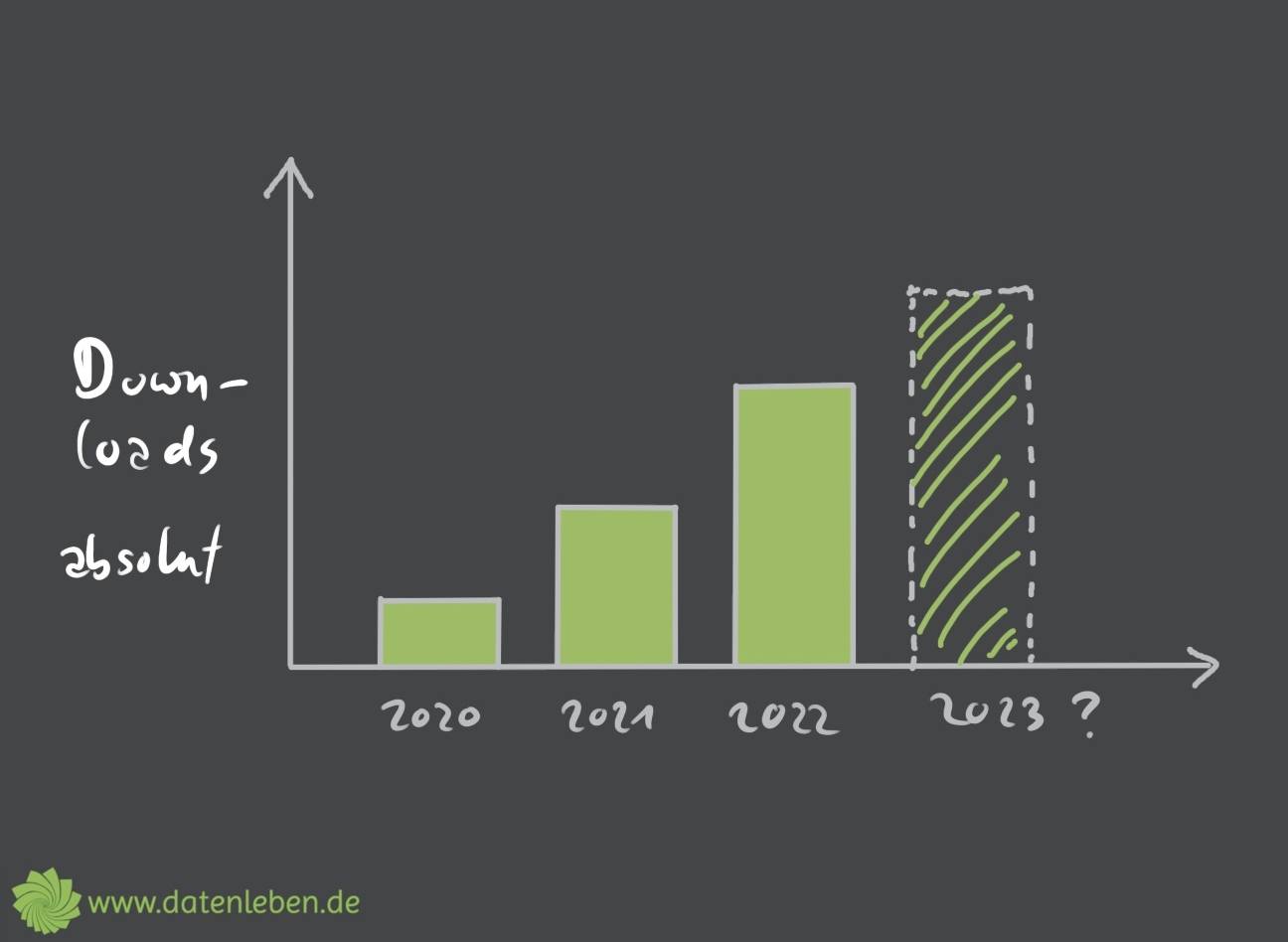
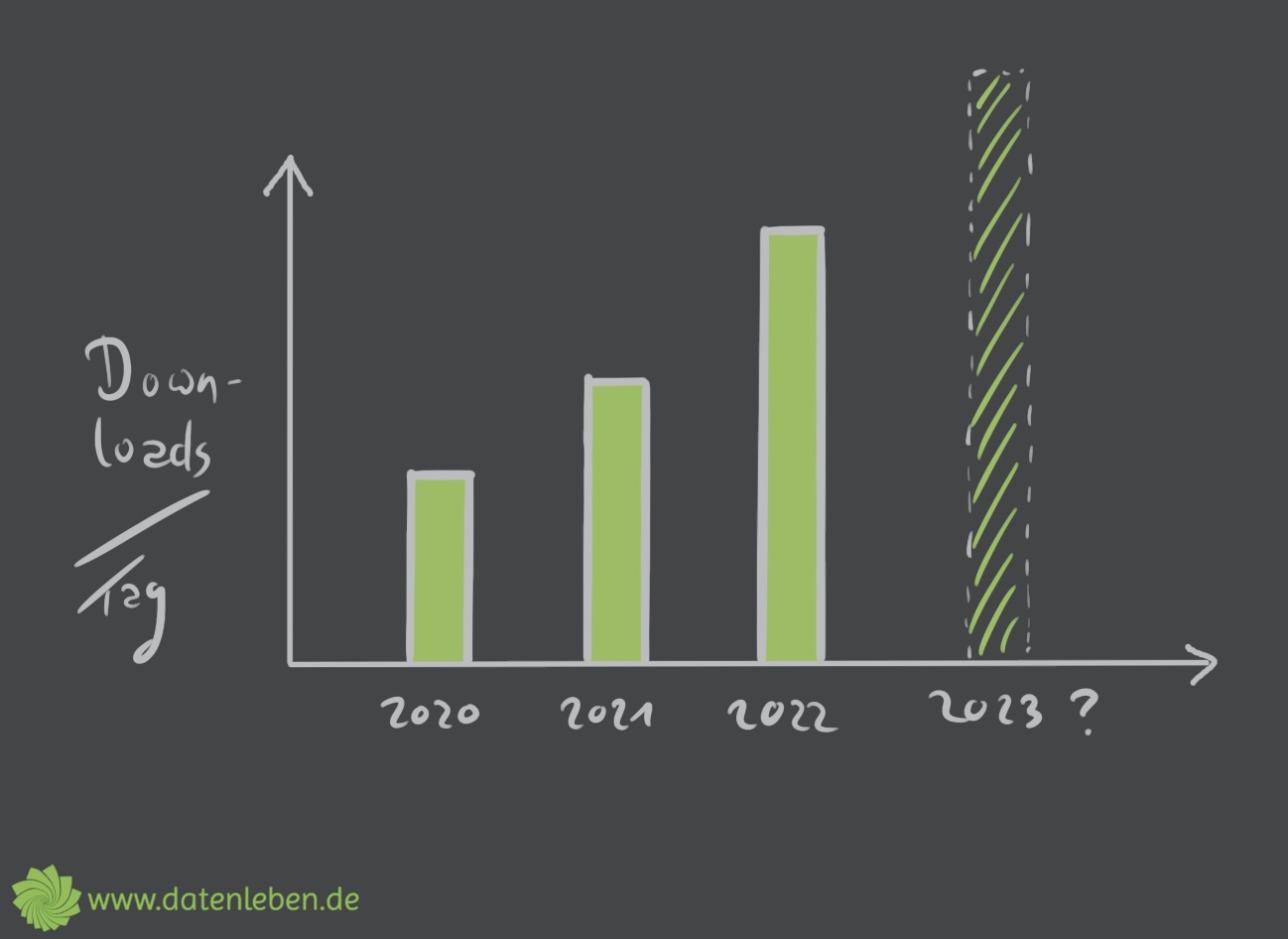
Janine: In den Shownotes findet ihr zwei Grafiken dazu, die das Ganze mal abstrakt, aber im richtigen Verhältnis darstellen.
Helena: Ja, und Janine hat sich dann auch noch angeguckt, was das jetzt für einzelne Folgen bedeutet. Ja, welche Folgen wurden denn besonders gerne angehört und wie messen wir das?
Janine: Ja, wir messen das auf folgende Art, also zum einen macht das Podlove-Plugin, das wir in unserem WordPress haben, worüber wir alles veröffentlichen. Da fallen verschiedene Daten an, und zwar die Gesamtdownloads, und es zeigt auch an, welche Folge so in letzter Zeit zum Beispiel runtergeladen wurde. Da gibt es immer so eine 30-Tages-Rückschau und eine schöne kleine Statistik, wo für jede Folge die jeweiligen Downloads 24 Stunden nach Veröffentlichung, zwei Tage, drei Tage, vier Tage, fünf Tage, sechs Tage, sieben Tage, zwei Wochen, drei Wochen, vier Wochen, etc. bis zu zwei Jahren in bestimmten Rhythmen dann festgehalten werden, das heißt, jede einzelne Folge hat gewisse Meilensteine, wo angegeben wird, wie viele Downloads bis zu diesem Zeitpunkt gemacht wurden. Was wir letztes Jahr da festgestellt haben, war, dass mit jeder neuen Folge meistens auch die Folge immer sehr erfolgreich war, also es sind stetig neue Hörende dazu gekommen, und die Folgen haben jeweils immer die Folgen davor übertroffen, und das war letztes Jahr ganz gut zu sehen. Dieses Jahr variiert das tatsächlich ein bisschen, so dass die Folgen auch mal vielleicht ein bisschen weiter zurückliegen, dass die neueste Folge, die erschienen ist, tatsächlich mal nicht auf Platz 1 ist, sondern vielleicht auf Platz 4 oder so, das schwankt da ein bisschen, und ich würde sagen, das liegt vor allem daran, dass je länger wir das machen, desto differenzierter wird es auch, und die Leute suchen sich, also vielleicht könnt ihr als Zuhörende das ja auch rückmelden, tatsächlich dann einzelne Themen aus und hören nicht mehr jede einzelne Folge, das ist so eine Theorie, die ich dazu habe. Meistens können wir aber tatsächlich auch thematisch ganz gut abschätzen, wie Folgen so performen, unsere Weihnachtsfolge hat zum Beispiel absolut wie erwartet performt, das heißt, wir haben schon gewusst, die wird definitiv nicht einen der oberen Plätze erreichen, immerhin ist sie am 24.12. erschienen, da haben viele Leute und auch in den Tagen danach eher etwas anderes zu tun, die, ja, wurde einfach nicht so viel gehört, wie die anderen Folgen kurz nach Veröffentlichung, und das kann aber auch mit dem Thema zusammenhängen, weil ich habe das gestern so ausgedrückt, es ist halt eher ein weiches Thema, das haben wir gesagt, war Trivia.
Helena: Ein weiches Thema, was ist denn weich für ein Thema?
Janine: Ja, also ich weiß, der Begriff ist vielleicht ein bisschen schwierig, aber es ist halt eher etwas schwammig vielleicht, vielleicht ein bisschen beliebig, vielleicht, weiß ich nicht, wie ich das gut ausdrücken kann, also wir hatten ja auch vorher bei der Folge über, Wie wird Autismus erforscht?, richtig geschätzt, die hat alle Meilensteine mit Eins abgeschlossen, zumindest bis einschließlich zur dritten Woche. Das hatten wir vorher auch so uns gedacht, weil es halt einfach thematisch sehr viel hergibt und auch ein Thema ist, das Menschen aus unterschiedlichen Gründen sehr stark interessieren kann, das vielleicht auch ein bisschen kontrovers, genau, vielleicht auch ein bisschen kontrovers verstanden werden kann. So, ja. Gut, das waren so Beobachtungen erst mal am Rande, aber Helena hat ja gefragt, welche Folgen denn wo gelandet sind, und ich habe mir die ersten drei Plätze rausgesucht. In 2022 an Gesamtdownloadzahlen hat den dritten Platz gemacht, unsere Folge 21 Python lernen, was besonders schön ist, weil die eigentlich nur aus 2021 ist, aber in 2022 immer noch sehr weit oben gelandet ist, was uns auch sehr freut, weil das ist auch ein schönes Thema. Auf Platz zwei ist gelandet unsere Datathon-Folge über unsere Teilnahme am Women and Data Science Datathon, die ja auch sehr gern gehört wurde, gerade am Anfang und auch jetzt immer noch wieder gehört wird, was wir auch ganz gut finden. Und Platz eins ist Folge 25 geworden, unsere Luftdaten-Folge.
Helena: Ja, das ist insofern überraschend, als dass ja oft Folgen, die irgendwie eher so sich mit Klima-Themen Beschäftigten nicht so gut abgeschnitten haben. Aber die Luftdaten gingen dann doch sehr gut.
Janine: Ja, Luftdaten gingen sogar so gut, ich hatte mich natürlich noch geguckt, das war in 2022 die Downloads, aber wie sieht das aus, wenn wir auf die Gesamtzahlen aller Jahre gucken? Und da ist tatsächlich die Luftdaten-Folge sogar auf Platz drei gerutscht.
Helena: Das heißt, die anderen sind aus anderen Jahren. Das sind ältere Folgen. Platz zwei und eins.
Janine: Genau, auf Platz zwei ist, das könnte man sich jetzt vielleicht schon denken, dann die Python lernen-Folge. Die hatte ja auch schon ein bisschen mehr Zeit, Downloads einzusammeln. Und Platz eins, wenig überraschend auch, ist unsere allererste Folge mit dem schönen Titel Data Science.
Helena: Ja, die Folge wurde so oft runtergeladen im Laufe der Zeit als erste Folge, dass wir uns letztes Jahr auch entschieden haben, eine nullte Folge davor zu setzen, einen Trailer, in dem wir dann auch sagen, ja, hört doch lieber die zwei Jahre datenleben-Folge, weil da erklären wir Data Science auch noch mal. Und die ist dann ein bisschen mehr in unserem aktuellen Stil. Das tragische daran, wenn die beliebteste Folge die erste ist, die man veröffentlicht, das ist ja die, wo wir noch nicht so eingespielt waren, wo wir alles noch ausprobieren mussten. Die zeigt noch nicht unbedingt das, wo wir jetzt stehen. Ich hoffe, wir haben was dazu gelernt im Laufe der Jahre, aber die erste Folge zeigt das halt definitiv nicht.
Janine: Ja, ich glaube auch. Also ich denke für mich selbst, wir sind etwas besser geworden. Aber ich glaube auch tatsächlich, dass wir ganz gut gestartet sind. Aber ja, ich hoffe, andere Menschen merken auch eine gewisse Entwicklung, die wir hingelegt haben.
Helena: Ja.
Unsere Lieblingsfolgen in 2022? (00:16:46)
Janine: Führt mich zu der Frage, was war denn so deine Lieblingsfolge in 2022?
Helena: Da musste ich erst ein bisschen drüber nachdenken, bin dann aber auch zu dem Ergebnis gekommen, wie offensichtlich auch die Hörenden im letzten Jahr, dass es die Luftdatenfolge ist, weil wir da zum einen eigene Messungen für gemacht haben und innerhalb dieses Messzeitraums dann auch völlig überraschende Dinge dazu kamen, wie zum Beispiel die Auswertung zum Vulkanausbruch und der Schockwelle, mit der ich, als wir damit angefangen hatten, überhaupt nicht gerechnet hatte. Und das Ganze auszuwerten und das zu erklären und dazu was zu machen, hat einfach unheimlich viel Spaß gemacht und deswegen war meine Lieblingsfolge im letzten Jahr die Luftdatenfolge.
Janine: Ja, im Prinzip könnte ich mich da eigentlich anschließen, auch aus den von dir genannten Gründen. Das hat total viel Spaß gemacht, sich damit zu beschäftigen, zwischendurch auch immer wieder. Das war ja nicht nur die Aufnahme oder die Recherche. Wir haben uns da ja sehr lange mit beschäftigt, um eben auch die Daten zu sammeln, auch inhaltlich. Hätte ich dann auch mal wieder Lust drauf, bei Gelegenheit.
Helena: Bin ich auch für. Gerne mal wieder eigene Messungen machen und auch gerne euch Hörenden dazu motivieren, auch mit uns Messungen zu machen. Das ist schön.
Janine: Ja, meine Lieblingsfolge, ich würde dann tatsächlich die Folge zum Thema Autismus wählen. Einfach weil, also es hat mir auf jeden Fall gezeigt, was ich am Podcast mag und schwierig finde. Und das fand ich interessant an der Folge. Also ich finde, wir haben eine gute Folge hingelegt, sonst hätten wir sie ja auch nicht veröffentlicht, wenn wir das nicht fänden. Aber es hat irgendwie auch gezeigt, wie schwierig das teilweise ist, öffentlich zu formulieren und zu wissen, das hören andere Menschen und die können auch interpretieren, was ich sage. Und wie kriege ich die Sachen vernünftig so formuliert, dass möglichst wenig Reibungsfläche vielleicht auch dafür entsteht, dass Menschen sich potenziell davon getroffen fühlen und gleichzeitig aber auch so formuliert wird, dass andere sich vielleicht abgeholt fühlen. Also ja, das hat für mich diese schwierige Balance, sich öffentlich zu äußern, einfach mal wieder deutlich gemacht. Und hinter dieser ganzen Sache steckt hier aber trotzdem, dass ich gerne Dinge erzähle und gerne Dinge vermittle und Wissen rüberbringen möchte. Und ja, das war so diese ganze Bandbreite an Emotionen, die damit zusammenhängen, einen Podcast zu produzieren, glaube ich.
Helena: Okay, faszinierend.
Janine: Ja, also in die Folgen fließen viele Gedanken auf verschiedenen Ebenen.
Helena: Ja, definitiv. Und gerade wenn es um Daten geht, die auch potenziell nicht immer nur positive Anwendung haben, dazu später mehr.
Feedback zu datenleben (00:19:39)
Janine: Wir haben tatsächlich hin und wieder von euch Feedback bekommen. Wir sagen das ja am Ende, sowas freut uns immer sehr. Ihr könnt gerne mehr Feedback bei uns abladen. Ein Feedback war auch zu der Folge über Autismus, dass die sehr positiv aufgenommen wurde. Das habe ich auf jeden Fall mitbekommen. Und ja, insgesamt dachten wir uns, wir lassen euch mal kurz an ein bisschen Feedback teilhaben. Deswegen haben wir uns drei Beispiele rausgepickt. In der Folge Können Computer malen, Folge 31, haben wir hin und wieder mal die Wolpertinger Ausmalbilder erwähnt, die Helena mit der Bildgenerierung, mit Stable Diffusion hergestellt hatte. Und wir wurden tatsächlich darum gebeten, diese auch mal zu veröffentlichen. Also insgesamt mit dem Feedback, dass die Folge echt sehr schön war und einen guten Einblick gegeben hat. Danke dafür. Und ja, wir haben die Bilder auch inzwischen veröffentlicht. Ihr findet sie auf unserer Seite im Blog. Ich werde das aber auch noch mal per Social Media rauswerfen, Schrägstrich rausgeworfen haben, wenn diese Folge wahrscheinlich veröffentlicht ist. Und ja, die hat Helena noch mal schön aufbereitet, weil aus der Bildgenerierung nicht so eine schöne Auflösung ausfällt. Deswegen hat Helena da noch mal eine Vektorgrafik draus gemacht und ihr könnt das dann als PDF herunterladen.
Helena: Genau, ich habe auch noch ein bisschen Feedback zu unserer Autismus-Folge bekommen. Zum einen bei den Begrifflichkeiten. Wir haben einfach völlig vergessen, die Begriffe Genotyp und Phänotyp zu erklären und zu benutzen. Genotyp ist einfach, welche Gene man hat und welche Gene beim Menschen vorliegen. Und Phänotyp ist das, was sich dann wirklich zeigt. Also in diesem Fall zum Beispiel die Symptome von Autismus. Und nur weil ein Gen da liegt, heißt es nicht automatisch, dass dieses Gen auch benutzt wird vom Körper, sondern das hängt eben von Umwelteinflüssen ab. Und diesen Teil wiederum haben wir allerdings in der Folge auch erklärt. Ich wollte nur noch mal nachreichen, dass es da auch Fachwörter zu gibt, weil ich darauf hingewiesen wurde. Und ein anderer Punkt, auf den wir auch noch hingewiesen wurden, ist eine Studie mit dem Namen Spectrum10K, die das Ziel hatte, die Genetik von Autismus noch genauer zu erforschen, als wir das bisher präsentieren konnten. Und diese Studie ist vor allen Dingen deswegen in die Kritik geraten, weil es ja eine dieser Studien war von Leuten, die selbst keine Autisten sind und in der Vergangenheit schon durch zweifelhafte Thesen über Autismus aufgefallen sind. Insbesondere, so wie die Studie angelegt war, Kritik oder Befürchtung bestehen, dass die Ergebnisse vor allen Dingen für Eugenik verwendet werden können. Und das ist nämlich genau dieser Nachteil an so Erkenntnissen wie, welche Gene spielen jetzt eine Rolle für Autismus, dass man einen Gentest machen könnte, um schon im Mutterleib bzw. vor der Geburt oder bevor man überhaupt die befruchteten Eizellen implantiert, feststellt, dass das Kind wahrscheinlich ein Autist wird. Und man das deswegen verhindern könnte, dass das überhaupt geboren wird. Und da wurden wir auf Mastodon drauf hingewiesen. Wir haben den entsprechenden Toot auch verlinkt, vielen Dank dafür. Ja, ich fände diese Anwendung von der Genforschung bei Autismus sehr erschreckend und ja, kann diese Form von Eugenik definitiv nicht unterstützen. Diese Studie Spectrum10k wurde allerdings mittlerweile pausiert und findet im Moment gerade nicht statt, was angesichts der Kritik auch ganz gut ist. Von daher hoffe ich mal, dass diese Gefahr jetzt zumindest für die nächste Zeit etwas reduziert ist bezüglich des Missbrauchs dieser Genforschungsergebnisse.
Janine: Das wäre definitiv wünschenswert und auch, dass Menschen sich ja nicht nur hinsichtlich Autismus über so etwas Gedanken machen, was Forschung für Konsequenzen hat. Der dritte Punkt, den wir uns so für die Feedbackschleife hier rausgesucht haben, war, unsere Folgen sind recht lang, teilweise auch sehr vollgestopft mit Inhalten, die wir interessant finden. Irgendwie auch alle immer zusammen gehören und wir mögen einfach gerne verschiedene Aspekte von Dingen beleuchten. Es wurde auch schon mal, ich weiß nicht, ob lobend oder erschrocken erwähnt, dass unser Quellenverzeichnis auch immer recht ausführlich ist. Ja, da geben wir uns auf jeden Fall Mühe, aber weil gerade die Folgen teilweise auch recht gehaltvoll sind, wurde sich schon mal gewünscht, dass wir die Fazits konkreter ziehen und versuchen, noch mal die Folgeninhalte grob zu wiederholen. Wir geben uns da auf jeden Fall sehr viel Mühe, aber ich glaube, es klappt nicht ganz immer, da so richtig konkret noch mal die einzelnen Aspekte zu wiederholen und auf alles einzugehen. Aber wir versuchen es auf jeden Fall, und gebt uns gerne weiter Feedback, ob das halbwegs funktioniert oder ob wir euch da noch mal ein bisschen besser abholen können und ihr da vielleicht doch noch ein paar klarere Gedanken mehr haben wollt. Aber ich muss ganz ehrlich gestehen, manchmal sind klare Gedanken gegen Ende der Aufnahme bei mir auch etwas aus.
Was nehmen wir mit aus 2022 an Themen oder Erkenntnissen? (00:25:14)
Janine: Kommen wir dann doch mal zu dem größten Abschnitt heute. Was nehmen wir mit aus 2022 an Themen und Erkenntnissen? Haben wir persönliche Erkenntnisse? Lass uns doch mal kurz über persönliche Erkenntnisse reden. Also ich habe jedenfalls welche. Ich habe auch versucht, das mit Daten zu machen. Ich gebe mir immer sehr viel Mühe, das ist letztes Jahr definitiv leider etwas ins Hintertreffen geraten, meinen Alltag, mein Gehirn und so weiter mit einem Bullet Journal zu organisieren. Und ja, eigentlich hilft mir das sehr gut. Manchmal scheitere ich daran trotzdem. Und ich glaube, letztes Jahr war so ein Jahr, wo das gescheitert ist. Ich habe mich dann dieses Jahr hingesetzt und möchte das wieder ändern. Das hat folgende Statistik zutage gefördert. Ich habe letztes Jahr gerade mal acht Bücher beendet. Das ist, ja.
Helena: Zählst du dabei nur selbst gelesene oder auch welche, die dir vorgelesen wurden?
Janine: Das waren selbst gelesene Schrägstrich welche, die ich vorgelesen habe.
Helena: Okay.
Janine: Ich würde aber mitzählen, wenn mir etwas vorgelesen worden wäre. Mir wird tatsächlich selten vorgelesen.
Helena: Auch nicht in Form von Hörbüchern?
Janine: Wenig. Wenn ich etwas höre, dann höre ich meistens Actual Plays oder Let's Plays, irgendwelche Podcasts, die sich mit gespieltem Pen & Paper befassen.
Helena: Ah, okay.
Janine: Ja, und das führt mich auch zu Teil zwei meiner persönlichen Statistik. Ich habe dann gedacht, naja, gut, irgendwas muss ich ja letztes Jahr gemacht haben. Wenn ich nicht gelesen habe, was dann? Dann habe ich mal die Spieltermine, also die Sessions zusammengetragen, an denen ich Pen & Paper entweder gespielt oder geleitet habe und bin bei satten 75 Terminen gelandet.
Helena: Das ist mehr als einmal die Woche.
Janine: Ja, mehr als einmal die Woche. Es sind neun Systeme, die ich in acht Settings gespielt habe.
Helena: Das ist ja auch sehr viel Verschiedenes. Ja.
Janine: Ja. Discord hilft in One Shots oder Few Shots zu landen und neue Systeme ausprobieren zu können. Es macht Spaß, dich da ein bisschen durchzutesten und zu gucken, wo man irgendwie hängen bleibt.
Helena: Ja, eine persönliche Erkenntnis war im letzten Jahr, dass es nötig ist, mal insbesondere an Heizenergie zu sparen. Und da fände ich es dann doch auch mal spannend, eine Datenbank anzulegen, die jeden Tag regelmäßig die Temperatur in meiner Wohnung misst an verschiedenen Orten. Und damit habe ich angefangen, das aufzunehmen. Auch dadurch befeuert, dass irgendwie zwischendurch mal die Heizung komplett ausgefallen war. Und es ja doch spannend ist, wie lange dauert es, wenn die Heizung komplett aus ist, wieder hochzufahren oder runterzufahren. Also beziehungsweise, wie lange dauert es für die Wohnung, bis es dann wieder normale Temperaturen enthält. Und das war dann auch ungefähr einen ganzen Tag, nachdem die irgendwie fünf Tage ausgefallen war. Das fand ich dann doch schon auch sehr lang. Das heißt, so richtig runterheizen, wenn man nicht da ist, kann man auch gar nicht. Also runterkühlen lassen, weil die dann überhaupt nicht mehr warm genug wird. Aber insgesamt ist meine Temperatur jetzt zu Hause deutlich niedriger, als in den Jahren davor. Ja, nur dass ich da keine Daten habe, um das zu vergleichen, weil ich die nicht gespeichert habe.
Janine: Und wie fühlt sich das jetzt an, wenn du sagst, das ist kühler?
Helena: Ja, jetzt habe ich halt eine Heizdecke fürs Sofa und nehme in Notfallzeit eine Fleecejacke, wenn ich arbeite und mir kalt wird. Das ist schon ein bisschen kalt, aber handelbar. Kann ich mit umgehen.
Janine: Ja, ich finde das spannend. Ich habe das auch von einigen Menschen gehört, die in den letzten Monaten auch versucht hatten, als die Heizperiode so richtig losging, einfach eine niedrigere Temperatur, als sie es sonst gehabt haben, zu heizen. Und ja, da haben einige, glaube ich, mit rum experimentiert. Ich persönlich bin ja ein Mensch, ich kann immer nicht viel machen, wenn mir kalt ist. Also ab einem gewissen Punkt hilft es mir nicht, Pullover anzuziehen, weil kalte Hände machen auch, dann funktioniert das Tippen wieder nicht mehr. Also es gibt irgendwie so eine Grenze. Ich glaube, das ist ganz spannend, die mal rauszufinden.
Helena: Ja, kalte Finger machen Arbeiten schwer. Das geht nicht. Also die Finger müssen warm sein. Aber es gibt Methoden, wie nach dem Kochen ist mir grundsätzlich immer sehr warm. Essen hilft grundsätzlich auch. Rausgehen, Spaziergang machen führt dazu, dass ich danach auch eher mich wieder warm fühle, selbst wenn es kälter in der Wohnung ist, als ich das vorher gewohnt war. Das sind so Dinge, die bei mir funktionieren.
Janine: Ja, und man darf auch nicht vergessen, man muss immer noch die Hausgesundheit im Blick haben. Also man sollte sich nicht unterbieten mit den Temperaturen, glaube ich, weil manche Häuser es einfach nicht vertragen, wenn sie zu kalt sind und nicht genug beheizt werden. Wir wohnen halt in einem Altbau mit feuchtem Keller. Not so gut.
Helena: Ja, klar, einfach, weil es dann sehr kalte Oberflächen gibt, wo sich dann Wasser sammelt und dann kann es schimmeln. Und wenn man das nicht sieht, weil da irgendwas vorsteht oder irgendwie die Tapete davor ist, ist das sehr ungesund. Also ich habe auch in jedem Raum ein Messinstrument, um mir die Luftfeuchte anzugucken und achte da auch drauf.
Janine: Ja, das ist sehr gut.
Was ist beim Maschinellen Lernen passiert? (00:30:44)
Janine: Kommen wir zu den Themen, für die wir auch hier sind und die uns dieses Jahr vor allem um die Ohren geflogen sind, die wir deswegen auch im Podcast schon besprochen haben, aber die auch teilweise seitdem Updates erfahren haben. Also es geht vor allem jetzt um Machine Learning, wie vorhin schon erwähnt. Das ist einfach mal ein bisschen explodiert, habe ich persönlich das Gefühl im letzten Jahr. Und ja, gemeint sind eben die Anwendungen mit sogenannter künstlicher Intelligenz, die dann plötzlich im großen Stil aufgetaucht sind. Es gab sie vorher natürlich schon, aber irgendwas ist passiert und plötzlich war es überall. Es ging mit der Bildgenerierung los und führte sich dann bis zu Mensch-Maschine-Interaktionen fort im Sinne von chatGPT. Deswegen dachten wir uns, wir greifen das Thema hier nochmal auf, weil wir es ja auch in Folge 31 hatten. Fangen wir doch mal mit der Bildgenerierung an.
Bildgenerierung und Stable Diffusion (00:31:41)
Helena: Genau, ursprünglich gab es Anfang des letzten Jahres oder im Frühling das Modell Dall-E, was jetzt Closed war, was man einfach benutzen konnte. Und dann gab es Dall-E-Mini, was viele Leute benutzt haben auf Social Media und dann Dinge geteilt haben. Aber die Ergebnisse waren jetzt, ja, so lala, um aus Text Bild zu generieren. Deswegen dachten wir, das wird das Thema für den Jahresrückblick. Am Ende ist es eine Folge geworden und seit wir die Folge veröffentlicht haben, ist Stable Diffusion herausgekommen. Und was sich zur ersten Version verändert hat, ist, zum einen kann es jetzt auch das Upscaling, das ist das, was Midourney vorher auch schon angeboten hatte, dass man, wenn man schon mal ein brauchbares Ergebnis hat, was einem gefällt, dann kann man dem auch sagen, ja, mach das jetzt mal groß, weil die Größe der Bilder war bisher sehr beschränkt. Und was wir vorhergesagt haben in unserer Folge, war die Funktion des sogenannten Inpainting, dass man innerhalb eines Bildes Elemente austauschen kann. Also, dass das meiste von dem Bild erhalten bleibt, aber dass einzelne Elemente nur getauscht werden können. Ja, war sehr naheliegend irgendwie. Deswegen ist es da jetzt auch drin.
Janine: Ich möchte da auch noch was ergänzen. Wir hatten ja im zweiten Teil der Folge zur Bildgenerierung auch noch so die kritischen oder kritischeren gesellschaftlichen Aspekte, wo ich auch darüber geredet habe, dass es da eben eine große Diskussion rund um Urheberschaft, Lizenzen und so weiter gibt. Und zwar meinte ich ja auch da schon, dass es ab dem Moment vielleicht kritisch sein kann, wo zum Beispiel Kunstwerke eines aktuell tätigen Menschen im Stile dessen reproduziert werden können durch die Machine Learning-Anwendung. Und da hat die Künstler*in Kelly McKernan auf Twitter auch etwas veröffentlicht, und zwar wurde der Prompt, also der Text für die Bildgenerierung eingegeben mit den Worten Art by Kelly McKernan of a woman with white curly hair and a white ribbon around her neck. Und dann wurde das Bild generiert und es sah tatsächlich aus wie Bilder von Kelly McKernan, nur dass dieses Bild nie von Kelly McKernan erstellt wurde. Und die Künstler*in präsentierte dann die Meinung dazu, wie kritisch das ist, dass so etwas gemacht werden kann und dass kunstschaffende Menschen hier auch potenziell Geld verlieren und um ihre Existenz bangen können, wenn die Bildgenerierung eben so weit geht. Und ich meinte, das wird noch eine große gesellschaftliche Diskussion und die ist jetzt so weit fortgeschritten, dass zum Beispiel in Amerika jetzt ein GoFundMe eingerichtet wurde, Mitte Dezember tatsächlich auch erst, wo gerade Geld gesammelt wird, damit kunstschaffende Menschen sich da zusammenschließen können, um auch anwaltlich dafür zu sorgen, dass eine bessere Gesetzgebung oder Regulierung von Bildgeneratoren geschaffen wird, um Kunstschaffenden eben nicht diese Existenzgrundlage nehmen zu können durch den Gebrauch ihrer Kunstwerke als Trainingsdaten für neue Bilder. Das ist sehr interessant. Auf der GoFundMe-Seite werden halt ein paar Punkte näher beleuchtet, wie die Kunstschaffenden dazu stehen und was sie auch für Ziele haben, um die Gesetzgebung in dieser Hinsicht voranzutreiben, dass da eine andere Grundlage für herrscht, dass die Firmen auch in Verpflichtung genommen werden, das eben mitzubedenken. Ich denke, diese Diskussion wird noch sehr viel weitergehen und fand das aber spannend, wie weit fortgeschritten es zu diesem Zeitpunkt jetzt da in Amerika in diesem Zusammenschluss von Kunstschaffenden schon ist. Eine zweite Bemerkung habe ich noch zur Bildgenerierung. Und zwar, so als Kulturwissenschaftlerin beschäftige ich mich ja gern mit den geistigen Themen und es bietet sich jetzt die Gelegenheit zu sagen, es sind die Geister in der Maschine. Es entstehen die ersten Mythen im Universum der neuronalen Netze, der künstlichen Intelligenz hier, was die Bildgenerierung angeht. Und zwar gibt es wohl eine rätselhafte, gruselige Frau, die auf verschiedenen Bildern auftaucht und immer wieder generiert wird offensichtlich. Ich habe den Artikel mal verlinkt, ich fand das schon mal ganz lustig, weil ja, hier entstehen Mythen und Geister und die Leute fragen sich, wie kann das entstehen? Und das hängt vielleicht auch damit zusammen, dass die neuronalen Netze doch irgendwo eine Blackbox bleiben von außen. Wir wissen ja nicht genau, was darin passiert und warum das so entsteht, wir können darüber nachdenken. Vielleicht interpretieren wir auch mal wieder nur einfach Muster und das sind Zufälle. Ja, aber die Menschen erzählen schon gleich wieder Geschichten darüber, das finde ich so faszinierend.
Musik und Machine Learning (00:36:45)
Helena: Ja, eine Sache, die ich für unsere damalige Folge auch schon mal Stable Diffusion ausprobiert hatte, war wissenschaftliche Grafiken damit zu erzeugen. Das ist komplett schief gegangen, da kam nur Unsinn bei raus. Es gab allerdings eine Gruppe von Leuten, die haben Stable Diffusion so wie es war genommen und es einfach weiter trainiert auf eine ganz bestimmte Sorte von wissenschaftlicher Grafik und zwar sogenannte Spektrogramme. Und ein Spektrogramm ist eine zweidimensionale Darstellung von der Frequenz eines Signals und auf der einen Seite gibt es dann zu einem bestimmten Zeitpunkt alle Frequenzen, die ein Signal drin ist und auf der anderen Achse ist dann halt, also das gibt es halt für jeden beliebigen Zeitpunkt, also sodass man insgesamt ja über die Zeit verschiedene Frequenzen hat und wenn man über die Zeit verschiedene Frequenzen hat, kann man daraus ja auch wieder Ton generieren. Die Leute, die das gemacht haben, haben das Ganze dann Riffusion genannt, also eine Mischung aus Stable Diffusion und Riff von Gitarren oder so und dann haben sie quasi das Ganze auf Musik trainiert. Dann kann man einen Text eingeben und in ihrem Beispiel war der Text Funk Bassline with a Jazzy Saxophone Solo und das Ganze hat ein Spektrogramm erzeugt und dieses Spektrogramm wurde dann wiederum in einen Ton überführt. Das möchte ich jetzt einmal einspielen. (Musik wird gespielt) Ja, das ist jetzt nur ein kurzes Schnipselchen, mehr fällt da jetzt nicht bei raus, deswegen haben es wahrscheinlich auch Riffusion genannt, weil mehr als ein paar Riffs kriegt man nicht draus, weil dafür sind dann 512 Pixel doch ein bisschen zu wenig, aber das ist klang ja schon ganz brauchbar. Ich meine klar, auf deren Website veröffentlichen die natürlich nur die Positivbeispiele, wo es besonders gut geklappt hat. Also selber ausprobiert habe ich es jetzt nicht, aber ich fand das eine lustige Methode, wie man, ja, auf Basis dessen, was es schon gibt, einfach was Neues machen kann, was dann plötzlich Ton rausfällt, obwohl man am Anfang nur Text reingeschmissen hat.
Janine: Definitiv.
Helena: Genau, bleiben wir beim Thema Musik und zwar ein Tool, was ich im letzten Jahr auch getestet habe, das grundsätzlich aber auch schon ein bisschen älter ist, ist demucs, ein Tool von Facebook Research und dem zur Grunde liegt ein AI-Modell, bei dem Musik, wie wir sie hören, wieder in einzelne Tonspuren überführt werden kann. Eine einfache Anwendung wäre, ja, wir haben irgendeinen tollen Popsong und wir wollen zu dem Lied Karaoke singen, aber es nervt ja, dass der Originalgesang immer noch da drin ist und dann gibt es halt zu beliebten Liedern irgendwie im Internet immer ganz viele Karaoke-Versionen, aber wenn das jetzt irgendwie ein Indie-Rock-Song ist, wo es das nicht so gibt, dann ist das ja schade, weil dann kann man das ja gar nicht so gut damit machen. Und da kommt jetzt demucs zum Einsatz, weil es wieder die einzelnen Tonspuren auseinanderdividiert. Das heißt, es kann den Gesang extrahieren aus dem Ton, beziehungsweise es kann halt auch so außer Gesang auch die Trommeln und die Basslinie und andere Sachen voneinander trennen. Und ja, außer daraus irgendwie Karaoke-Versionen zu machen, kann man eben dann auch eine Grundlage schaffen, mit der man dann Remixer erzeugen kann. Und zwar als Beispiel habe ich das Lied Happy Happy Game Show von Kevin MacLeod mitgebracht. Das enthält kein Gesang, aber es ist eben ein Lied, das für so Anwendungen wie so ein Podcast einfach frei benutzt werden kann. Deswegen kommt das jetzt und ich spiele einmal den Anfang von dem Lied selber ein. (Musik) Genau, das war jetzt das Lied. Und jetzt kann man zum Beispiel nur sich die Drums anhören. (Musik) Oder nur die Instrumente. (Musik) Und es gibt noch die Basslinie. (Musik) Und das ist schon sehr spannend. Alles zusammen wird dann ein vollständiges Lied, aber so in Einzelteilen, ja, kann man vor allen Dingen damit andere schöne Dinge machen. Und ich bin gespannt, wie ich das selber nochmal einsetzen werde, weil das war irgendwie so ein Tool, was ich letztes Jahr gefunden hatte, wo ich dachte, ja, damit will ich unbedingt was machen. Und es wurde auch letztes Jahr auch hier noch ein besseres Modell veröffentlicht. Das heißt, so gesehen passt das auch in 2022, weil auch hier Fortschritte passiert sind. So, ein anderes Tool, was sich mit Musik beschäftigt, wo es sich die Tage oder vor ein paar Wochen gesehen hatte, nennt sich Pop2Piano. Und das soll dann aus Popmusik ein Piano-Cover machen. Und wenn man jetzt irgendwie selber gerne Keyboard oder Klavier spielt und möchte, dass andere Leute dann dazu singen können, ja, dann gibt es manchmal die Noten von bekannten Liedern zu kaufen, aber auch hier wieder nicht einfach für alles. Und da hilft dann dieses Tool, wo man dann ein Lied reinschmeißen kann und dann kriegt man eben die Noten. Wenn ich mir das anhöre, dann enthält das zu viele Tasten gleichzeitig, die man auf dem Klavier drücken muss. Da muss man vielleicht dann selber nochmal ein bisschen drüber gehen und die eigentlichen relevanten Punkte extrahieren. Ja, da spielen wir jetzt nichts ein, weil die auf ihrer Webseite tatsächlich einfach Popsongs veröffentlicht haben, für die wir jetzt natürlich keine Lizenzen haben. Und uns auch gar nicht erst damit auseinandersetzen möchten.
Janine: Ja, auf jeden Fall auch sehr spannend. So mit so Musik und der ganzen Möglichkeit, was Machine Learning da anbietet, habe ich mich auch noch überhaupt nicht beschäftigt.
Helena: Ja, also ich finde es mega spannend, weil ich ja durchaus auch öfter was mit Musik mache und mal gucken, was ich da noch so draus ziehe und draus bastel.
Janine: Da bin ich auch gespannt drauf. Ich muss da auf jeden Fall dran denken, wenn das so gut klappt, die Instrumente voneinander zu separieren. Also ich meine, Podcastende kennen das Problem ja vielleicht, dass man manchmal eine Audiospur hat, wo alle gleichzeitig reden und man schwer Sachen schneiden kann und das meistens sehr viel Aufwand fordert. Da wäre es ja eigentlich schön, wenn es da vielleicht auch ein Modell gibt, das Stimmen voneinander separieren und einzelne Tonspuren erstellen kann
Helena:. Ja, das wäre auf jeden Fall nützlich für diese Anwendung. Das kann demucs jetzt allerdings nicht. Das kann immer nur eine Spur als Gesang erkennen. Und da kann dann auch schon mal eine Violine drauf landen, wenn man Pech hat. Also nicht wie bei jedem Lied, das ich getestet hatte, war es super, aber das war schon ziemlich gut.
ChatGPT und Sprache zu Text (00:43:38)
Janine: Ja, apropos ziemlich gut. Wir hatten jetzt Bilder, wir hatten Musik und jetzt kommt die Sache mit dem Text auf jeden Fall noch mal. Da ist nämlich auch einiges passiert, gerade was Sprache zu Text auch angeht. Also die Bildgenerierung ist ja Text zu Bild und Sprache zu Text ist auf jeden Fall auch etwas gewesen, was mich ein bisschen länger beschäftigt hat, wo ich immer mal versucht habe zu gucken, was sind denn gerade die interessanten Optionen, um zum Beispiel Transkripte für den Podcast zu erstellen. Die waren alle ehrlich gesagt mäßig gut. Also es gab Modelle, die das gemacht haben, es gab auch Optionen, selber ein Modell trainieren zu können auf der eigenen Sprache, was dann ja prinzipiell besser funktioniert, weil ja das eben optimal abgestimmt ist und auch vielleicht mal Ungenauigkeiten besser erkannt werden, als wenn es ein Modell ist, was allgemein auf Sprache trainiert ist. Aber die Ergebnisse waren doch immer alle noch sehr durchwachsen und es hat, ja, die Nachbereitung von Transkripten hat immer noch sehr viel Zeit erfordert und wir hatten uns ja eigentlich mal vorgenommen, auch unseren Podcast relativ barrierearm zu gestalten, weswegen wir von vornherein sehr intensiv Shownotes erstellt haben und das Transkript wäre so der nächste Schritt gewesen, den wir eigentlich auch gern gemacht hätten und deswegen habe ich da immer mal nach geguckt, aber es hat sich einfach nicht ergeben, weil ja der Arbeitsaufwand doch größer wäre und die intensivere Shownotes-Erstellung doch irgendwo der leichtere Weg war. Das ist jetzt wahrscheinlich anders. Es gibt jetzt Whisper, auch von OpenAI und damit haben wir hier auch rumgetestet. Ja, du kannst die MP3 da reinwerfen mit Sprache und dann kommt der Text raus. Das sind auch verschiedene Modelle. Das größte Modell braucht wie Stable Diffusion im Ursprung 10 GB auf der Grafikkarte und arbeitet etwas länger, als die MP3 dauert. Also das ist ein bisschen mehr als eins zu eins und ist aber auch das genaueste und das habe ich einmal jemanden mit einer MP3 durchspielen lassen und ich war vom Ergebnis extrem überrascht. Es kann Groß-Kleinschreibung, sinnvolle Kommasetzungen, die Ähs werden rausgelassen im Text, was ich auch gut finde, was ich auch so machen würde, weil sonst wäre der Text auch einfach irgendwie unleserlich und lang, also länger als er dann eh schon ist bei so einer ganzen Folge Podcast. Und ja, das war einfach extrem gut, was daraus gekommen ist und ich musste sehr, sehr wenig nachbearbeiten. Da war ich doch sehr überrascht und das ist auch einer der Punkte, warum für mich 2022, was Machine Learning angeht, doch ziemlich einen Schritt nach vorne gemacht hat.
Helena: Ja, ich bin gespannt, wie das dann klappt für unseren Podcast im Einsatz.
Janine: Wenn es geklappt hat, dann findet ihr unter dieser Folge auch einen Link, wahrscheinlich, ich weiß noch gar nicht, wir haben noch gar nicht darüber geredet, wie wir es machen, aber wahrscheinlich auf dem PDF vielleicht, wo noch das Gesamttranskript ist oder das Transkript steht dann direkt in den Shownotes, aber wahrscheinlich eher das. Also ja, ihr merkt, noch keine Gedanken gemacht. Auf jeden Fall wird diese Folge da einmal durchlaufen und dann gucken wir mal, wie wir das am Ende umsetzen. Ich bin gespannt.
Helena: Ja, ich auch.
Janine: Die zweite Sache, die mit Text zu tun hat, ist eben, was ich vorhin schon kurz erwähnte, so als Buzzword oder Bullshit-Bingo, kann man ja schon fast sagen, chatGPT.
Helena: Genau, wir hatten früher ja schon mal in einem der früheren Jahresrückblicke von GPT-3 erzählt, also dem dritten GPT-Modell, was Texte schreiben konnte. Ja, und chatGPT ist jetzt einfach die nächste Version davon.
Janine: Und ich wette, wir müssen gar nicht groß erklären, was das ist. Ihr seid bestimmt alle damit konfrontiert worden und manche hatten vielleicht auch schon die Schnauze voll, dass halb Social Media oder dreiviertel Social Media einfach nur noch voll war von Auszügen von chatGPT, was das Ding jetzt schon wieder gesagt hat und was man nicht alles damit machen kann. Die Bandbreite ist riesig. Ja. Ich will es daher auch gar nicht so großartig ausweiten, aber chatGPT ist so ein Ding, das uns auch wieder an viele Fragen führt. Ja, man könnte fast sagen, damit es mal wieder sehr bewusst und ganz öffentlich und für alle nachvollziehbar eine gewisse Grenze überschritten wurde, wo eigentlich Zeit ist, jetzt kurz anzuhalten und zu überlegen, was machen wir da eigentlich und was machen wir damit eigentlich so als Menschen. Die Optionen sind groß und die Gefahren halt eben auch. Ein Punkt, was so in Richtung Gefahren geht oder Sachen, auf die man sehr achten muss, den hat, finde ich, Svea Eckert sehr gut beschrieben. Das ist eine Journalistin beim NDR, die auch den Podcast She Likes Tech, der Podcast über Technologie, macht. Und zwar sagte sie in einem Interview, worauf man achten muss, ist die Technikgläubigkeit der Menschen. Dass wir aufpassen müssen, dass Menschen jetzt nicht anfangen, die Antworten, die chatGPT auf die verschiedenen Fragen, die gestellt werden, einfach ungefragt zu übernehmen, unhinterfragt zu übernehmen. Weil, ja, chatGPT wirft Informationen zusammen, die in beeindruckender Zeit und auch in teils beeindruckender Wortwahl generiert werden, weswegen auf der Oberfläche ein Anschein von Akkuratheit entsteht oder Akkuratess. Ein schönes Wort, das ich mal auf einem Festival gelernt habe. Und das birgt halt einfach die Gefahr, dass Informationen nicht mehr hinterfragt werden und wir dadurch in eine Schleife geraten und diese Sachen eben einfach übernehmen. Das ist etwas, finde ich, sehr Wichtiges, was man bei chatGPT so im Hintergrund haben sollte. Andererseits gibt es natürlich auch schöne Optionen. Es kann einem vielleicht Wege verkürzen, die Angst vor dem leeren Blatt für Schreibende minimieren, indem man einfach einen Anfang generieren kann, den man dann überarbeitet. Es kann Arbeitsprozesse abnehmen. Es kann aber auch verhindern, dass Arbeit für Menschen zur Verfügung steht. Und das ist eben genau die gleiche Diskussion, wie dann auch bei der Bildgenerierung dahinter steckt. Das sind so, ja, verschiedene Eindrücke, die damit zusammenhängen. Auch wie bei der Bildgenerierung, wo wir ja gesagt haben, dass verschiedene Plattformen, die sich auf Kunstschaffende spezialisiert haben, verboten haben, künstlich generierte Bilder dort zu veröffentlichen. Genauso, was ist zum Beispiel mit Stack Overflow passiert. Dort wurde verboten, Antworten von chatGPT zu veröffentlichen, weil doch bitte die Menschen die Antworten auf die Probleme, die andere am Computer haben können, geben sollen und nicht diese vermeintlich künstliche Intelligenz. Spannend ist noch vielleicht als kleine Randnotiz, dass ich einen Link gefunden habe, wo berichtet wurde, dass Forschende angefangen haben, mit chatGPT oder mit dem Modell hinter chatGPT Alzheimer zu erkennen, weil Alzheimer als Erkrankung sich vor allem in den Sprachmustern von Menschen bemerkbar machen kann. Und Texte von diesem Modell daraufhin untersuchen zu lassen, würde wohl zutage fördern können, welche Menschen potenziell an Alzheimer erkrankt sind oder erkranken können oder noch sehr früh im Stadium sind oder in der Entwicklung der Erkrankung. Und ja, da gab es wohl, soweit ich mich jetzt noch richtig erinnere, eine 80-prozentige Trefferquote.
Helena: Ja, ich meine, 80 Prozent hat immer noch den Nachteil einer riesigen Menge Leute, die nicht betroffen sind. 80 Prozent ist ja erstmal nur für die Leute, die davon betroffen sind. Aber wenn viel, viel mehr Leute keinen Alzheimer haben, werden die 20 Prozent am Ende die Mehrheit der Menschen sein. Also es ist noch nicht genug, um es wirklich einsetzen zu können, aber es ist eigentlich, gerade Alzheimer gehört schon zu den Sachen, je früher man die erkennt und Gegenmaßnahmen ergreift, desto besser funktionieren diese Gegenmaßnahmen. Und wenn da jetzt in die Richtung geforscht wird, ist das auf jeden Fall spannend. Generell ist Einsatz von KI in Medizin ein spannendes, aber auch riskantes Thema.
Janine: Absolut.
Helena: Wo wir bisher noch keine Folge drüber gemacht haben, aber vielleicht gibt es die ja irgendwann.
Janine: Das so viel zu den Eindrücken, was bei diesen großen Themen von Machine Learning passiert ist. Ich könnte da noch ganz viel mehr drüber sagen, aber ich glaube, so lange wollen wir gar nicht die Folge dann noch machen.
Was gab es sonst noch beim Maschinellen Lernen? (00:52:27)
Helena: Genau. Ja, ich rede noch mal über andere Themen. Was es sonst noch so beim maschinellen Lernen gab. Also eine der Hauptanwendungen für maschinelles Lernen ist das Klassifizieren. Also feststellen ist etwas in einer bestimmten Kategorie. Also zum Beispiel Fotos und gucken, ja, was ist denn auf dem Foto? Ist da eine Katze drauf oder was auch immer? Oder ist da ein Straßenschild drauf, das mir irgendwie sagt, ich soll so und so schnell fahren oder ich darf da nicht lang fahren? Dafür wird es viel eingesetzt und da gab es im Laufe der Jahre auch immer wieder so Beispiele wie, ja, jemand hat einen kleinen Aufkleber auf ein Straßenschild gemacht und dann ist der Tesla-Autopilot darüber gefahren, obwohl er da gar nicht lang fahren durfte, laut dem Straßenschild. Und jeder Mensch erkennt sofort, was das Straßenschild meint, aber die KI war zu dumm dafür, weil sie sich leicht austricksen lässt. Was es im letzten Jahr auch dann Neues gab in diesem Bereich, war eine Veröffentlichung, bei der ausprobiert wurde, kann man absichtlich solche Fehler einbauen in so eine KI. Also wenn man jetzt irgendwie ein Dienstleister ist oder jemand, der irgendwo arbeitet und böse Absichten hat, kann man beim Training der KI dann eine Hintertür einbauen, dass die einen, wenn man ein bestimmtes Symbol zeigt, immer durchlässt, obwohl man eigentlich gar nicht durch darf. Und die Antwort war ja, man kann eine Hintertür einbauen und die ist nicht auffindbar, weil man die ja nur finden würde, wenn man weiß, welches Symbol da gezeigt werden muss, auf welche Art und Weise diese KI manipuliert werden muss. Und selbst wenn man zufällig darauf stößt, dass das so ist, kann man das ja nicht davon unterscheiden, dass es ja auch genug andere Bugs gibt, die dazu führen, dass die KI sagt, das ist das und das, obwohl es das gar nicht ist. Deswegen, so undetectable Backdoors sind ein reales Risiko, sollte jemand mit bösen Absichten beim Training dabei sein. Und ein anderes Thema, das wir in der Vergangenheit auch schon mal hatten, war das Thema Proteinfaltung. Das gilt jetzt im Wesentlichen als ein mit KI gelöstes Problem. Und zwar wurde 2021 AlphaFold2 veröffentlicht und das kann so genaue Vorhersagen zu Proteinstrukturen machen wie sonst keine Methode. Und die ist schon nah an der Messgenauigkeit dran. Der spannende Teil ist jetzt allerdings, dass man trotzdem Vorannahmen machen muss. Man muss wissen, welche Proteine usw. wo sind und muss da schon viele Messungen für gemacht haben. Das heißt, die kann nicht für jedes beliebige Protein die Faltungsstruktur vorhersagen. Und da gab es 2022 dann eine neue Veröffentlichung von Wang et al. Die haben das nochmal insofern verbessert, dass man weniger von diesen Vormessungen machen muss. Und die haben da auch eine Proteinstruktur vorhergesagt mit ihrem Modell, die sie dann mit Röntgenstrukturanalyse validiert haben. Proteinfaltung ist spannend, weil je nach die Wirkung eines Proteins im Körper hängt halt davon ab, wie die Struktur ist. Und das ist insbesondere für Medikamente ein spannendes Thema.
Gibt es was Neues zum Wetterprojekt? – Ja! (00:55:32)
Janine: Wir wollten ja Folgen quasi thematisch noch ergänzen, die wir so im Laufe des Jahres hatten. Wir springen jetzt aber tatsächlich zurück bis ins Jahr 2020.
Helena: Oh, das ist lange her. Was war 2020? 2020 haben wir diesen Podcast gestartet.
Janine: Ja, genau. Und zwar in Folge 5 haben wir über das Wetterprojekt gesprochen, das Helena zusammen mit Pecca gemacht hat, die auch dabei war in der Folge.
Helena: Das Projekt selber hat 2018 stattgefunden im Rahmen des europäischen Summer-of-Weather-Code, also das Sommer-von-Wetter-Code, als Anspielung auf den Google Summer of Code, wo man Open-Source-Projekte macht und das bezahlt wird für ein paar Monate. In diesem Fall wurde es vom Europäischen Zentrum für mittelfristige Wettervorhersagen bezahlt.
Janine: Und wir hatten dann 2020 darüber eine Folge gemacht, wo es hauptsächlich darum ging, auch wie Datenvisualisierung funktioniert und zwar von ganz bestimmten Daten, nämlich von Wahrscheinlichkeiten. Die beiden haben zusammen in diesem Projekt eine Darstellungsart entwickelt, wie Wetterwahrscheinlichkeiten so abgebildet werden, dass sie potenziell intuitiver und besser verstehbar sind, als die relativ festgesetzten Darstellungen und Erzählweisen, wie sie in aktuellen Wetterberichten bestehen. Ich hoffe, ich habe das jetzt halbwegs gut zusammengefasst und verstehbar. Es geht um die Wahrscheinlichkeiten von Wetter und wie sich das auf uns auswirkt und was wir daraus lesen können. Und ja, dieses Projekt konnte damals nicht weiter verfolgt werden über dieses Summer School hinaus, weil irgendwann der Zugriff auf die Daten, die vom Europäischen Zentrum für mittelfristige Wettervorhersagen bereitgestellt wurden, abgelaufen war. Und die Daten waren eben nicht öffentlich zugänglich. In unserer Folge über offene Daten haben wir erzählt, wie toll es wäre, wenn es mehr Daten gäbe, mit denen Menschen halt tatsächlich coole Dinge machen können, die anderen Menschen helfen und so weiter. Ja, deswegen ist das eingeschlafen. Aber was ist 2022 passiert, dass wir jetzt darüber reden?
Helena: Seit 2022 veröffentlicht das Europäische Zentrum für mittelfristige Wettervorhersagen, dieses tolle, lange Titel, jetzt tatsächlich auch die wahrscheinlichkeitsbasierten Vorhersagen als Open Data. Also es gab auch schon vom Deutschen Wetterdienst Wettervorhersagen, die man einfach runterladen konnte und frei benutzen konnte. Aber die enthalten halt nicht diese Wahrscheinlichkeiten, wie wir sie dargestellt haben. Und seit letztem Jahr sind die eben veröffentlicht, die, die wir haben wollten. Allerdings mit ein paar Nachteilen. Zum einen werden die Daten in ihrer einfachsten Form im Sinne von der Datendarstellung her einfach nicht von der Verständlichkeit einfach veröffentlicht. Und zwar gibt es die Daten dann einfach für die ganze Welt auf einmal zum Download. Und ein Nachteil ist im Vergleich zu den kommerziell verfügbaren Daten ist, dass die Auflösung nur 0,4 Grad hat, also Grad im Sinne von Längengrad und Breitengrad. Die Daten eigentlich aber in 0,1 Grad Auflösung existieren würden. Und so Informationen wie die Wolkenbedeckung steht nicht in diesen Daten drin. Die hatten wir vorher halt über die Programmierschnittstelle bekommen, aber die ist nicht veröffentlicht worden. Und jetzt gibt es nur sowas wie Wasserdampfmenge in der Atmosphäre als Datenpunkt, woraus man vielleicht die Wolkenbedeckung berechnen kann. Das muss ich noch herausfinden. Aber das Ganze gilt jetzt eben, ja, dass man das runterladen kann. Und dazu hat das ECMWF ein Python-Paket veröffentlicht, mit dem man dann einfach die Daten runterladen kann. Und ja, die Wetterfeuerzeugersoftware, die wir dann 2018 mal entwickelt haben, muss jetzt umgebaut werden. Und ich bin da auch schon bei. Und ein Ziel für dieses Jahr von mir ist dann, das wieder online gehen zu lassen und zu testen. Und ja, wenn das Ganze funktioniert, würden wir auch nochmal zu wahrscheinlichkeitsbasierten Wetterfeuersagen eine Folge aufnehmen. Und dann können wir nicht nur theoretisch darüber reden, sondern auch ganz praktisch erklären, was wir da machen und wie die Webseite funktioniert. Und dann könnt ihr den auch alle ausprobieren.
Janine: Das wäre auf jeden Fall sehr, sehr cool.
Was haben wir noch gefunden? (01:00:05)
Helena: So, ein weiterer Punkt, den ich letztes Jahr gesehen hatte, Anfang des Jahres, war, wurde eine Grafik in der New York Times veröffentlicht, bei der die Corona-Inzidenzen über die Zeit dargestellt wurden. Und zwar war die Zeitachse dann nicht irgendwie so eine normale lineare Achse, sondern es wurde als Spirale dargestellt. Und die Spirale war dann so, dass Januar auf Januar gelegt wurde, sodass man direkt den Januar mit dem Januar vergleichen konnte, aber auch global sehen konnte, wurde es mehr oder weniger. Und wir haben ein Blogpost verlinkt, wo es darum geht, diese schöne Darstellung von Zeitdaten mit Jahresvergleich in R nachzubauen. Ja, und eine Sache, die mir beim Jahresrückblick erstellen auch noch eingefallen ist, ist, dass ja im Frühling auch noch so ein volles Hype-Thema Wordle war, also das Spiel, wo man fünf buchstabige Wörter erraten sollte. Und das ist so ein Spiel, das taucht irgendwie scheinbar alle paar Jahrzehnte mal auf. Und das hatte früher einfach einen anderen Namen. Und zwar hieß das dann, oder die Frage, welche Wörter man idealerweise am Anfang nehmen sollte, um herausfinden, welche Buchstaben fehlen, um alle Möglichkeiten schnell abzudecken, ist bekannt als Jotto-Problem. Und das ist schon Jahrzehnte alt. Und deswegen gibt es auch schon seit Jahrzehnten wissenschaftliche Veröffentlichungen zu den optimalen Wörtern, zumindest auf Englisch. Da haben wir eine von verlinkt.
Janine: Du meinst, damit man besser cheaten kann, falls man immer noch im Wordle-Rausch ist?
Helena: Ja, weiß ich nicht, ob das Cheaten ist. Teilweise sind das Wörter, wo man erstmal diskutieren muss, ist das ein Wort.
Janine: Das erinnert mich jetzt an viele lange Abende mit der Familie beim Scrabble-Spielen. Schlagt das nach. Wenn es nicht im Buch steht, ist es nicht erlaubt.
Helena: Aber wenn es in einem Roman steht, ist es dann erlaubt, auch wenn es nicht im Wörterbuch ist.
Janine: Uh, Glatteis würde ich sagen.
Was erwartet uns wohl in diesem Jahr? (01:02:09)
Janine: Dann sind wir tatsächlich jetzt einmal durch und kommen zu dem Punkt, wo wir uns fragen, was erwartet uns wohl in diesem Jahr? Falls ihr euch fragt, was erwartet uns in diesem Jahr bei datenleben? Ja, wie vorhin gesagt, im Prinzip bemühen wir uns um einen barrierearmen Zugang zu unserem Podcast. Dazu gehören natürlich auch immer Bildbeschreibungen. Ich habe irgendwann angefangen, die Folgencover im WordPress mit Bildbeschreibungen zu hinterlegen. Ich denke, einige Bilder in den Shownotes sind auch mit Bildbeschreibungen hinterlegt, aber das Geständnis hier ist auf jeden Fall noch nicht alle und vor allem nicht von Anfang an. Das ist definitiv etwas, wo ich dran arbeiten möchte, wenn ich die Folgen einpflege, dass da jetzt auch von Anfang an Bildbeschreibungen bei den neu erscheinenden Folgen drin stehen, möchte aber tatsächlich auch in die Vergangenheit reichen und dort die Beschreibungen noch nachliefern. Genau, damit wir an diesem Punkt einfach auch das Maß an barrierearmen Informationszugang bieten können, das wir bieten möchten. Und ja, da werde ich mich auf jeden Fall bemühen, dieses Jahr das ein bisschen aufzuarbeiten und zu verbessern. Dann ist euch vielleicht aufgefallen, dass wir eine YouTube-Folge haben, und zwar die Folge 31 Können Computer malen? haben wir auch mit Unterstützung von Stella auf YouTube veröffentlicht, die für uns das Video zusammengestellt hat und die Untertitel. Die Sache werden wir so mal verfolgen. Wir werden das auch potenziell wiederholen bei Folgen, die sehr bildlastig sind, die viel mit Beschreibungen von Bildern arbeiten, weil wir das sinnvoll finden, dass man das auch parallel sehen kann, während es gehört wird. Und ja, da spielen wir auf jeden Fall noch ein bisschen mit rum, denn wir finden das auch noch ein bisschen spannend. Vielleicht gibt es ein kleines Projekt, dass wir einen Teaser für die Folgen auch auf YouTube haben, die dann eben zu den Podcast-Folgen verlinken, um einfach ein bisschen mehr Reichweite zu generieren. Ja, und was noch spannend ist, finde ich, im Jahr 2023 wird das Thema Fediverse, also wir sind ja inzwischen auch auf Mastodon, aber Mastodon ist nicht das einzige im Fediverse. Und durch diese ganze Sache mit Twitter, die ich hier jetzt nicht näher ausführen werde, bewegen sich Menschen inzwischen durch das Fediverse und versuchen das zu erkunden, was es da an Optionen gibt. Und vor allem auch Menschen, die sich vielleicht sonst grundsätzlich mit dieser Struktur des Zugangs und der Vernetzung unter verschiedenen Dingen noch nicht beschäftigt haben. Und da bin ich einfach mal ganz gespannt drauf, wie sich das weiterentwickelt und wie die Menschen anfangen, damit zu arbeiten. Und ja, Mastodon wird inzwischen auch schon häufiger in den Nachrichten erwähnt als Quelle.
Helena: Sehr schön.
Janine: Da möchte ich auf jeden Fall selber ein bisschen Blick drauf haben und habe mir auch zu dem Zweck schon vorgenommen, das Fediverse ein bisschen zu erkunden und habe jetzt mit Bookworm noch angefangen.
Helena: Was ist das denn?
Janine: Das ist eine Sache, die im Prinzip das Einpflegen, Tracken und Besprechen von Büchern, die gelesen werden, ermöglicht. Die nicht ganz so offene Variante ist das, was die meisten wahrscheinlich kennen, Goodreads. Aber das ist mit Amazon verknüpft, deswegen habe ich da immer die Finger von gelassen. Und ja, seit etwas mehr als einem Jahr, ein Jahr, neun Monate oder so, gibt es, glaube ich, Bookworm im Fediverse, sodass Menschen eben auch Sachen aus Goodreads exportieren können und sich auf schöne kleine Server setzen können. Und das wird gerade auch immer größer. Und ja, da bin ich mal ganz gespannt und gucke mal, ob ich meinen Lesekreis da auch langsam hinkriege. Jedenfalls gibt es da viel zu entdecken. Und ich denke, das machen Menschen dieses Jahr.
Helena: Bin auch gespannt. Also ich erwarte auch für das aktuelle Jahr, dass es beim Thema Machine Learning weitergeht, nach all den ganzen Sachen, wie mit chatGPT wird rumgespielt oder mit Stable Diffusion. Gehe ich mal davon aus, das wird mehr in Anwendungen überführt werden. Gerade Microsoft ist groß da drin, chatGPT irgendwie einzusetzen. Oder die wollen das zumindest und haben es angekündigt. Da bin ich gespannt, was daraus wird. Und ich hoffe mal, dass auch so was wie Whisper vielleicht einsetzbar wird für sowas wie Sprachassistenten, die man aber zu Hause hostet, ohne dass man die ganze Zeit abgehört wird. Bisher gab es da noch keine zufriedenstellende Software für. Und ich bin mal gespannt, ob das auf Basis von Whisper jetzt auch möglich wird und ob das in diesem Jahr auch kommt.
Fazit (01:07:00)
Helena: Ja, Fazit. Ein Fazit ist ja, unser Podcast ist vital und fit, weil wir immer noch am Wachsen sind. Und wir gehen jetzt mit großen Schritten auf den dritten Geburtstag zu. Und es freut uns weiterhin, dass Menschen, immer noch mehr Menschen dazukommen und auch die alten Folgen immer noch rege gehört werden. Das ist sehr motivierend dabei, wenn wir neue Folgen aufnehmen.
Janine: Ja, dann versuche ich mich mal, wenn du das Podcast-Fazit quasi gemacht hast, an dem Machine Learning-Fazit. Ja, wie wir durch Themen wie Bildgenerierung, Text zu Musik oder Sprache zu Text oder Interaktion mit einem Modell, was einem Sachen empfiehlt, was man kochen soll, oder welche Fehler man in seinem Programm-Code hat, etc. pp., was wir daran auf jeden Fall gesehen haben. Machine Learning ist 2022 wirklich ziemlich breit gefächert gewesen und hat ziemlich viel Einfluss auch auf den Diskurs gehabt. Und ich bin sehr gespannt drauf, wo dieser Diskurs noch hin führt. Es gibt auf jeden Fall Stellen, auf die man achten muss, womit man umgehen muss. Die haben wir auch erwähnt, was zum Beispiel die Rechte von Künstler*innen angeht, deren Basis einfach in den Trainingstaten liegt oder auch wie wir mit Inhalten umgehen, die diese Modelle generieren und all das, das haben wir jetzt auch noch mal erwähnt und finde ich auch immer wieder wichtig zu erwähnen, wenn man über so etwas redet. Und das Nächste, was wir vielleicht thematisch noch hatten, ist das Wetterprojekt geht gerade weiter und ich hoffe auch wirklich, wir kriegen da Erkenntnisse, über die wir dann noch mal reden können und es stellt sich da nicht noch mal was in den Weg. Und ansonsten würde ich sagen, erwartet uns hoffentlich ein angenehmes 2023. Wobei, naja, es liegen da so Themen im Hintergrund, über die wir jetzt hier nicht geredet haben. Aber ja, es wird weitergehen. Das ist glaube ich jetzt das Positivste, was ich nach diesem Abrutschen noch sagen kann.
Nächste Folge: Zum Thema Heuschnupfen am 25. Februar (01:09:07)
Helena: Ja, genau. Und es geht weiter am 25. Februar mit unserer nächsten Folge und zwar wird es da um Statistiken zum Thema Heuschnupfen gehen, also um Allergien und wie die sich so zu bestimmten Zeiten im Jahr verändern.
Call to Action (01:09:23)
Janine: Und wenn ihr uns weiterhören möchtet, auch 2023 hören wir nicht auf, diesen Standardblock mit dem Call-to-Action zu haben, folgt uns, solange es noch möglich ist, auf Twitter unter @datenleben oder solange ihr möchtet. Oder kommt rüber zu Mastodon und folgt uns unter @datenleben@podcast.social. Ja, wir sind umgezogen. Wir sind jetzt auf der Instanz, wo mehr Podcasts sind. Besucht auch gern unsere Webseite www.datenleben.de. Hinterlasst uns unbedingt Feedback, wenn ihr Lust dazu habt. Wir würden uns darüber sehr freuen. Und ihr könnt uns auch als Data Scientist buchen für Analysen oder Projekte. Egal, was es ist, falls ihr Fragen habt oder Themen, die euch interessieren, dann schreibt uns.
Helena: Ja, dann bleibt mir nur noch für eure Aufmerksamkeit zu danken und bis zum nächsten Mal. Tschüss!
Janine: Tschüss!