dl031: können computer malen?
Es geht endlich mal wieder um Maschinelles Lernen und zwar um Neuronalen Netze, die durch Texteingabe Bilder generieren können. Was ist das und welche Anwendungen gibt es? Wir haben viel Spaß beim Experimentieren gehabt und möchten euch erzählen, was uns dabei aufgefallen ist. Über welche Probleme sind wir dabei gestolpert? Und wie funktioniert das überhaupt auf der technischen Seite? Darüber und welche Gedanken das noch so auslöst, reden wir in dieser Folge.
Intro (00:00:00)
Thema des Podcasts (00:00:18)
Willkommen zu unserer 31. Folge beim datenleben-Podcast, dem Podcast über DataScience!
Wir sind Helena und Janine und möchten euch mitnehmen in die Welt der Daten.
Was ist Data Science? Was bedeuten Daten für unser Leben? Woher kommen sie und wozu werden sie benutzt?
Das sind Fragen, mit denen wir uns in diesem Podcast auseinander setzen.
Dabei gehen wir Themen nach, die uns alle und die Welt, in der wir leben, betreffen.
Thema der Folge (00:00:42)
- Dieses Mal geht es um Künstliche Intelligenz... allerdings vielleicht etwas mehr um das Kunst in Künstlich
- Und vielleicht auch nicht wirklich im Intelligenz
- Ihr ahnt vielleicht, es geht zur Abwechslung mal wieder um Maschinelles Lernen: das generieren von Bildern mittels KI
- Wir reden erstmal im Allgemeinen Teil darüber, was das ist, welche Anwendungen es gibt und was ihr Ziel ist
- Danach erzählen wir euch von unseren Experimenten und Erfahrungen mit diesen Anwendungen
- War haben nämlich welche herausgepickt und die auch ein bisschen miteinander verglichen
- Dabei sind wir auch über altbekannte "Probleme" gestolpert
- Schließlich wird Helena dann auch nochmal etwas zur Funktionsweise, also dem technischen Hintergrund, erzählen
- Und ehe wir dann zum Fazit kommen, möchte ich nochmal allgemein ein paar Ethische Konfliktpunkte anreißen
Warum ist das Thema interessant? (00:01:49)
- Dieser Aspekt vom Maschinellen Lernen/Künstlicher Intelligenz wird dieses Jahr besonders viel besprochen
- seit anfang des jahres wird immer wieder darüber geredet und immer wieder neue anwendungen und verbesserungen
- im letzten halben jahr hat sich da viel getan
- Über das Generieren von Bildern mit sogenannter Künstlicher Intelligenz reden aktuell sehr viele
- Das Thema ist sowohl spannend als auch nicht unumstritten
Einspieler: Gibt es da nicht was im Internet... ? (00:02:40)
- Ton einer ankommenden Nachricht. "Freue mich auf die Runde, bis nachher!"
- Ah, verdammt, was mache ich jetzt, ich habe nicht alles beisammen? Ich schreibe Pia...
- Geräusche von Tasten. Habe mal wieder einen Termin verpennt. Ich leite nachher online die Rollenspielrunde und brauche noch stimmungsvolle Bilder? Wo kriege ich denn jetzt so schnell passende her? Hast Du Ideen? Habe nur noch eine Stunde!
- Komm schon, komm schon, antworte! trommeln auf dem tisch ... ping
- Pia per Sprachnachricht: Sorry, ich weiß du hast Sprachnachrichten, aber ich bin grad zu faul zum tippen. Oh Mist! Gibt es nicht was im Internet?
- Getippte Antwort: Bis ich alles durchwühlt habe, ist die Stunde rum und es passt auch nie richtig
- Pia per Sprachnachricht: Nimmst du nicht für Namen immer so Generatoren? Fantasynamensgeneratoren? Gibt es sowas nicht auch für Bilder?
- Getippte Antwort: Du bist grandions! Natürlich, habe vor ein paar Wochen mal so etwas getestet, ich guck mal, ob's das bringt.
- Pia per Sprachnachricht: Und, wie ist es gestern gelaufen?
- Getippet Antwort: Total gut. Habe vor lauter Bilder generieren fast den Anfang der Runde verpasst, aber war großartig. Hat so richtig schön gepasst. Zugegeben, wir mussten auch lachen, ein paar der Nebenfiguren hatten echt schräge Gesichter. Danke nochmal, für die Idee, war super!
Was ist dieses Bilder generieren - ganz grob gesagt? (00:05:19)
- Es ist eine Maschine - neuronales Netz - da wirft man Text rein und am ende kommt ein Bild heraus
- die benutzende person beschreibt ein bild, tippt ein text ein und der computer generiert aus dem text ein bild
- Das neuronale Netz folgt also der Anleitung und denkt sich nichts selbst aus, ist also keine wirkliche Intelligenz
- Das Stichwort hierfür ist aus dem Englischen: "text to image"
- Was gibt es für Anwendungen?
- Craiyon (dall e mini) https://www.craiyon.com/
- Kostenlos, über Webseite nutzbar und generiert 9 Bilder auf dem eingegebenen Text
- Witzig, aber sahen teilweise creepy aus, vor allem Gesichter
- Das war aber noch keine ganze Folge wert, aber seitdem hat sich einiges getan
- Alle großen IT-Firmen arbeiten gerade an solchen Projekten
- Microsoft
- Turing Bletchley, nicht kostenlos veröffentlicht
- Beispiele einsehbar: https://www.microsoft.com/en-us/research/blog/turing-bletchley-a-universal-image-language-representation-model-by-microsoft/
- Problematisch: Beispiele sind vermutlich gut ausgesucht, potentieller Ausschuss nicht sichtbar von Außen
- Kann auch andere Sprachen als Englisch
- Midjourney https://www.midjourney.com/home/
- Kann kostenlos benutzt werden, aber auch zusätzliche mit Geld erweitert werden
- Öffentliche Beta in deren Discord: man kann dort über einen Bot Bilder generieren
- Erzeugt werden 4 Bilder und es werden Progress sowie Zwischenschritte angezeigt
- Dann kann man zu einem der 4 Blder weitere ähnliche Bilder erzeugen lassen, oder eins davon hochskalieren lassen
- Man hat als Benutzender also mehrere Möglichkeiten, wie man damit weiter arbeitet
- Es kriegt auch Gesichter sehr gut hin
- Night Cafe https://creator.nightcafe.studio/
- Erzeugt nur "gemalte Bilder"/Gemälde
- Kann durch diese "Einschränkung" besser trainiert werden, weil weniger verschiedene Optionen zur Verfügung stehen
- Dadurch ist es spezialisierter und auch billiger in der Erzeugung des Modells
- Dream Studio https://beta.dreamstudio.ai/dream
- Kostenlos nutzbar, von Stability AI, die mit anderen Gruppen zusammengearbeitet haben
- stable diffusion modell dahinter, das runtergeladen werden kann - kostenlos
- Kann aber auch auf deren Webseite genutzt werden, ist auch schon ziemlich gut
- Dieses Modell hat Helena vorallem benutzt
Was kann mensch damit anstellen? (00:11:45)
- Haben uns natürlich gefragt, "Was kann mensch damit anstellen?" und ein bisschen rumexperimentiert
- Viele, deswegen Beispiele rausgepickt: htable diffusion, midjourney und craiyon
- Helenas Experimente mit stable diffusion:
- Erstmal das Modell, also das neuronale Netz stable diffusion runterladen
- Ist eigentlich für Grafikkarten (darauf wird es laufen) mit mindestens 10GB Speicher
- Helenas hatte nur 6GB, was auch für andere Leute das Problem war
- Deswegen gab es eine vereinfachte Version für 6GB Grafikkarten, hierbei waren die Modelle weniger genau und konnten ihre Zahlen weniger präzise speichern
- Dann konnte es losgehen mit dem Bilder generieren
- Erster Test: Namen von Menschen, die Helena kennt, denn im Trainingsdatensatz können diese ja auch drin sein und dann generiert werden
- Allerdings hat das nicht funktioniert
- Gelingt aber mit berühmten Menschen (Albert Einstein etc.), vermutlich weil genug Bilder in den Trainingsdaten waren

- Zweiter Test: Ausmalbilder für Kinder
- Idee aus der Bildershow vom Microsoft-Tool
- Mit Elefanten: Ging gut, hat aber auch einmal den Elefanten schon selbst ausgemalt
- Es waren gute Ausmalbilder, aber teilweise ein bisschen kompliziert, eher für Erwachsene
- Mit Wolpertinger (Fantasiegestalt, setzt sich aus verschiedenen Tieren zusammen): Aufgrund der großen Vielfalt von Wolpertingern sehen die Ausmalbilder auch entsprechend absurd aus, aber erkennbar Wolpertinger
- Manche Wolpertinger sehen allerdings ein bisschen aus wie sehr plüschige Motten

- Dritter Test: Schöner Sonnenuntergang am Strand
- Beeindruckend waren, dass die Reflexionen der Sonne im Wasser waren sogar richtig
- Sonnenuntergang vom Flugzeug probiert, aber keine eigene Erfahrung, um das mit der Realität vergleichen zu können

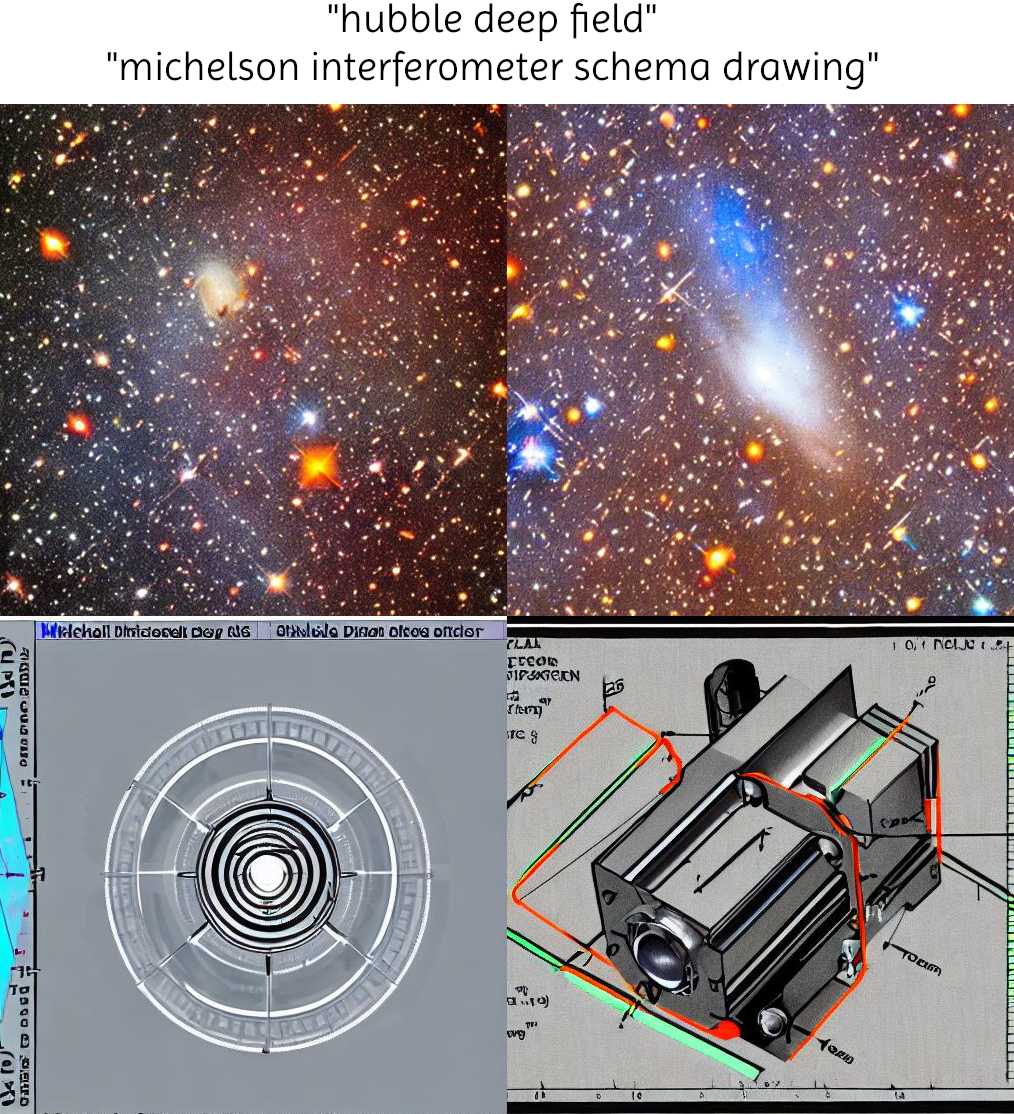
- Vierter Test: Hubble Deepfield
- Deepfield aufnahme, ist, wenn das Weltraumteleskop sehr weit entfernte Galaxien und Sterne aufnimmt
- Generierung klappt tatsächlich sehr gut, Helena war sehr begeistert
- Fünfter Test: Wissenschaftliche Schemazeichnungen
- Das ist komplett schief gegangen
- Sechster Test: map of tasmania
- Es ergibt eine karte, die sehr grobe Form hat gestimmt
- Siebter Test: Person mit bunten Haaren auf einem Pferd sitzend
- Es kam heraus ein Pferd mit 4 Beinen, ein Mensch mit 2 Beinen, allerdings fraglich, warum man die 2 Beine auf diese Weise sieht
- Anzahl Füße und Hufe korrekt, aber ein menschlicher Fuß war am Pferd, ein Huf am Menschen
- Gesicht komplett schief gegangen

Was kann bei der Generierung Probleme bereiten? (00:20:04)
- Gesichter:
- Ein Weg, um sicher zu stellen, dass Darstellungen von Menschen scheitern, ist, sie in einer komplexen Szenerie darzustellen, oder mehrere Menschen auf einem Bild
- Eine einzelne Person funktioniert am besten
- Bei Szenerien nicht, als würde die Wichtigkeit der Person dann nicht mehr im Vordergrund stehen
- Schrift:
- Ergibt einfach keinen Sinn
- Es generiert Schrift, aber sie ist teilweise nicht lesbar und wenn sie lesbar ist, ergeben die Wörter keinen Sinn
- Semantik:
- Probleme bei Szenerien, Beispiel: Wolpertinger on a bus
- Ergebnisse verschieden: Wolpertinger sitzen im Bus, sind auf den Bus aufgemalt oder sitzen oben drauf
- Es war halt sprachlich nicht eindeutig
- Semantik ist wichtig!

- Weiteres Beispiel: gray cat grass kann auch verschiedene Ergebnisse erzeugen, bereits wenn man im Trainingsdatensatz danach sucht
-
- Graue Katze auf grass (gray cat grass - alle Begriffe wurden benutzt)
-
- Graue Katze (gray cat - grass wird hier unterschlagen)
-
- Graues grass (gray grass - cat wird hier unterschlagen)
-
- Katzengras (cat grass - cat wird hier als nur als "cat grass" interpretiert, also die Pflanze, gray wird unterschlagen)
- Ursache: die KI hat keine Semantik vorgefunden in Form von Adjektiven, Satzzeichen etc. also die Worte einfach frei interpretiert
- Um nur Graue Katzen auf Grass zu bekommen, müsste man spezifisch "gray cat on grass" oder "gray cat, grass" eingeben
- Weitere Sprachexperimente: White House (ergibt das Weiße Haus, den Regierungssitz in den USA), black house ergibt schwarze Häuser und green house ergibt Gewächshäuser (direkte Übersetzung aus dem Englischen), für grüne Häuser müsste "Green colored House" eingegeben werden

- Helena hat versucht mit Midjourney Ideen für die Umsetzung ihres Halloweenkostüms zu bekommen
- Eingabe war: Frauen auf denen Pilze wachsen; hat verschiedene Sachen rausbekommen
- Davon hat sie eines hochskalieren lassen, was dann immer creepyer aussah
- Midjourney konnte größere Bilder erstellen "upscaling", erzeugt auch mehr Präzision
- Eins hat sie dann als Ausgangspunkt für weitere Bilder genutzt, Gesichter anfangs sehr neutral, in den hochskalierten Bildern wurden nicht nur die Details besser, die Person hat dann auch gelächelt
- Das ist auch von den Personen her das beste Bild, in der Hinsicht ist Midjourney schon beeindruckend

- Bias:
- Bias ist ein Vorurteil oder eine Vorannahme, die sich auch in Daten niederschlagen können (siehe Folge dl004: racial profiling)
- Dazu gehört die Diskriminierung von Minderheiten oder eben die aktive Marginalisierung - Diskriminierung betrifft ja nicht nur Minderheiten im Sinne von kleineren Gruppen, sondern eben auch größere Gruppen
- Inzwischen wird fast schon selbstverständlich darauf verwiesen, dass Trainingsdaten einen Bias haben
- Ein Beispiel, dass wir gefunden haben, war "most attractive men in the world"
- Hat fast ausschließlich identisch aussehende Männer ergeben: weiß, mittel alt, gepflegter kurzer Bart
- Wahrescheinlich sind Bilder ähnlich aussehender Männer im Interent oft damit beschriftet
- Ein zweites Beispiel, das auch jemand probierte war "professionell hairstyles" und "unprofessionell hairstyles"
- Viele Frisuren, auch von weißen Personen, bei beiden Begriffen, Differenzierung zwischen professionell und unprofessionell war nicht ganz ersichtlich
- Die Idee diese Begriffe auszuprobieren rührt daher, dass festgestellt wurde, dass in Suchmaschinen bei "unprofessionell hairstyles" überwiegend Schwarze Menschen gezeigt werden und bei professionell überwiegend weiße Menschen, was eben ein gesellschaftliches Urteil ist
- Das konnte aber so mit der Bildgenerierung nicht rekonstruiert werden, aber der Bias ist klar, dass hier fast ausschließlich weiße Menschen in den Bildern erzeugt werden

- Genderbias und genderneutrale Sprache:
- Getestete Begriffe waren "doctor" (Ärzt*in) und "nurse" (Krankenpfleger*in)
- Obwohl Englisch an sich eine genderneutrale Sprache sein kann, wurden bei doctor nur Männer oder Schriftzüge dargestellt
- Bei nurse wurden ausschließlich Bilder von Frauen generiert
- Gesellschaftliche Klischees führen also auch hier dazu, dass Vorurteile so stark reproduziert werden

Wie funktioniert die KI der automatische Bildgenerierung? (00:32:00)
- Jetzt haben wir schonmal einen Überblick darüber, was das ist und was man damit machen kann
- Jetzt ist die Frage wie das alles zu stande kommt, was wir beobachtet haben: warum ist das so?
- Oder anders gesagt: Wie funktioniert so eine Anwendung auf der technischen Seite?
- Die KI/das neuronale Netz, das hinter der Bildgenerierung steckt, ist gar nicht so leicht, deswegen erstmal ein einfacheres Konzept, das noch nicht stable diffusion ist:
- Man erstellt ein Bild aus zufälligem Rauschen
- Nutzt dann ein Neuronales Netz das 'vorhersagt' was ein gutes Bild sein würde
- Und dann nutzt man ein anderes Neuronales Netz das gute Bilder erkennt
- Und mit letzterem trainiert man das erste Netz so, dass es besser wird, und zeigt auch nur die an, die als 'gut' benannt werden
- Die diffusion Modelle hingegen erzeugen nicht einfach ein Bild
- Was ist Diffusion? In der Chemie: wenn man einen Tropfen Tinte in Wasser packt, verteilt sich diese erst in Schlieren, bis das Wasser dann gleichmäußig bläulich gefärbt ist
- Das ist Diffusion: ein definierter Zustand wird immer verschwommener
- Was macht Stable Diffusion? fängt bei einem komplett verschwommenen Bild an und wird immer detaillierter
- Weil die Verteilung auch anfangs zufällig ist, nennt man das auch Rauschen
- Es geht bei dem diffusion modell darum letztendlich das Rauschen zu entfernen
- Es sagt das Rauschen in einem Bild vorraus, statt direkt ein schönes Bild zu erstellen, wird erstmal nur berechnet wo es rauscht
- Das funktioniert, weil man das prognostizierte Rauschen und das Eingangsbild wiederum
voneinander abziehen kann, und dann kommt ein Bild heraus mit potentiell
weniger Rauschen - Das wird dann viele Male hintereinander gemacht, für verschiedene Rauschlevel, und so lassen sich Bilder generieren

- Janine findet, dass das so klingt, wie auch beim Malen vorgegangen werden kann
- Sie startet mit einer Farbfläche, zum Beispiel grün für Wald und ergänzt dann helle und dunkle Töne und arbeitet so aus dieser Fläche nach und nach die Details raus
- Aber nur Rauschen entfernen hat ja noch nichts mit einem Text zu tun
- Diese Rauschentfernung durch das neuronale Netz kann so gemacht werden, dass das neuronale Netz den Text kennt
- Und anhand der Bildbeschreibung kann es dann Dinge, die beschrieben wurden, stärker hervorheben, sodass da dann weniger Rauschen ist
- Macht man die Rauschvorhersage mit einem Neuronalen Netz, dass auch auf Bildbeschreibungen trainiert wurde, erkennt es Rauschen, das nicht zu dem Text passt besser
- Wenn man jetzt aber beide verfahren gleichzeitig umsetzt, also einmal mit Text das Rauschen ermitteln und einmal ohne Text, dann ist das Neuronale Netz sensitiver an der Stelle wo das beschriebene Objekt im Bild ist, und man kann beim
vergleichen beider Rauschprofile dann die Stelle verstärken, wo das gewünschte Objekt im Bild drin ist - Beide Netze erkennen überall gleich das Rauschen, aber das neuronale Netz, dass den Text hat, erkennt an der Stelle, wo die Katze sein sollte, dass dort keine Katze ist, das Rauschen also besonders stark ist
- Wenn jetzt beide Bilder verglichen werden, kann gesehen werden, wo die Katze hin soll und kann an dieser Stelle das Ergebnis verstärken
- Wenn man beides gleichzeitig macht, werden die generierten Bilder deutlich präziser
- Dazu hat Helena auch ein gutes Video gefunden: Computerphile, YouTube
- Die Verstärkung ist der eigentliche Trick dieses Verfahrens
- Spannend sind auch die vielen Zwischenschritte mit Bildern, die dabei entstehen
- Das führt dazu, dass man auch mit einem richtigen Bild anfangen kann, und es dann durch den Text verändern kann
Wie funktioniert das mit den Trainingsdaten? (00:40:40)
- Um das neuronale Netz zu trainieren, braucht man viele Bilder und Texte dazu
- Ein Arbeitsschritt, der beim Training gemacht wird, ist auf Bilder Rauschen schichtweise hinzuzufügen
- So kann das neuronale Netz die umgekehrten Schritte "üben" und daran schon trainiert werden
- Aber dafür braucht man einen guten Datensatz, stable diffusion wurde auf einem Teil des Datensatzes Laion-5b trainiert
- Laion-5b ist ein Datensatz mit 5 Milliarden Bild-Text-Paaren: https://laion.ai/blog/laion-5b/
- Woher kommen die Bild-Text-Paare? Aus dem Internet!
- Letztlich wird wie bei einer Suchmaschine das Internet durchsucht, und Bilder mit Beschreibungstexten werden gespeichert
- Weil das Internet voller Pornographie ist, werden solche Bilder mit dem safety-tag 'NSFW' (Not Safe For Work) markiert, damit man
diese Bilder beim Training aussortieren kann - Weiteres Problem: sichtbare Wasserzeichen im Bild (z.B. URLs), die auch nicht miteglernt werden sollen werden ebenfalls markiert
- Die meisten Bilder sind dabei auch kleiner als 512px.
- Problem: Was ist ist wenn die Bildbeschreibung nicht zum Bild passt?
- Dafür wurde ein Modell names CLIP verwendet, das bereits vorher existierte, um von vornherein diese Bilder auszusortieren
- Der Datensatz besteht aber jetzt nicht aus Bildern, sondern enthält Metadaten und die Links zu den Bildern, sodass die dann für das Training direkt runtergeladen werden können
- Modellerstellung: Einige 100 Millionen Bilder wurden dann benutzt um stable diffusion zu trainieren
- Modell wurde anfangs auf 256px Bilder trainiert, später dann mit einer Auflösung 512px weitertrainiert; das ist auch die finale Größe der generierten Bilder
- Rechenleistung fürs Training hat einige 100k€ gekostet, weswegen es cool ist, dass sie das Modell veröffentlicht haben, denn das ist nichts, was man mal eben zu Hause machen kann
- Wie gut wäre dieses Modell bei Deep Fakes? Können realistisch Personen gefaked werden oder bräuchte es dazu noch eine andere Software?
- Dafür gibt es eigentlich sehr spezifische Software, die nur auf die Person zum Beispiel trainiert wird, die gefaked werden soll
- Berühmte Personen können mit stable diffusion schon erkennbar generiert werden, aber meistens ist gut zu sehen, dass die das nicht wirklich sind
- Das könnte sich allerdings ändern, wenn die Datengrundlage der Bild-Text-Paare wächst, aber sicher nicht für Privatpersonen
- Beschränkungen, die stable diffusion selbst nennt:
- Limitierungen: kein perfekter Fotorealismus aktuell möglich, Textgenerierung scheitert, komplexe Kompositionen und Menschen sind noch schwierig, es ist nur auf Englisch, sehr viel NSFW-Content, identische Bilder aus verschiedenen Quellen (dominantier im Ergebnis)
- Sie weisen auch selbst darauf hin, dass in den Trainingsdaten ein Bias vorhanden ist
- Also eigentlich alles, was uns auch aufgefallen ist
Worüber sollten wir nachdenken? (00:49:06)
- Das führt zu der Frage: Worüber sollten wir uns vielleicht Gedanken machen beim Einsatz solcher KIs?
- Bias in den Daten ist natürlich nur ein Aspekt, über den wir uns als Gesellschaft gedanken machen sollten (Repräsentation, Diversität, etc.)
- Nicht nur durch den Bias der tatsächlichen Trainungsdaten kann Diskriminierung entstehen, sondern auch durch den Ausschluss von Worten wie "Down Syndrom" bei der Text zu Bild Generierung
- Daneben gibt es noch weitere
- Auch Deep Fakes hatten wir schon angesprochen, fotorealistische Nachbildungen durch eine KI können menschen durchaus in die irre führen
- Zwar aktuell so nicht möglich, aber es könnte noch aktuelle werden und allgemein ist es jetzt schon etwas, wo wir über den Umgang mit irreführendem Bildmaterial nachdenken müssen
- Hier liegt das Problem vor allem darin, dass Nachrichten, Informationen etc. manipuliert werden können, um mit sogenannten alternativen Fakten einfluss auszuüben
- Aktuell werden tatsächlich unsichtbare Wasserzeichen in automatisch generierte Bilder gesetzt
- Das könnte natürlich auch umgangen werden, wenn wer böse Absichten hat, aber es erschwert es zumindest
- Die sind hauptsächlich dafür, dass keine generierten Bilder zum Training für die neuronalen Netze benutzt werden
- Sind mein Bilder in Trainingsdaten? Diese Website sagt es dir: https://haveibeentrained.com/
- Wer nicht möchte, dass eigene Portraits in diesem Datensatz sind, kann diese Webseite nutzen
- Datenschutz: Bilder aus einer Krankenakte sind im Datensatz aufgetaucht
- Urheberrecht: Sind urheberrechtlich geschützte Bilder enthalten und was bedeutet das?
- Insgesamt wirft das viele fragen auf, gerade was Kunst angeht
- Wer hat denn das urheberrecht auf generierte Bilder, wenn sie auf urheberrechtlich geschützten Werken basieren?
- Aktuell: Die Person, die es generiert, hat das Urheberrecht
- Helena findet, es ist nichts anderes, als sich von anderen inspirieren zu lassen
- Aber wie sieht das mit aktuell tätigen Künstlerinnen aus? Frage ist nicht nur, wem gehört das Bild, sondern was ist damit auch möglich, wo sind die Grenzen?
- Kunst und Kommerzialisierung: Einiget Plattformen für Kunst haben den Upload von KI generierter Kunst untersagt
- Da schwingt durchaus die Angst mit, auch in finanzieller Hinsicht vom Markt verdrängt zu werden
- Es gibt aber auch andere Bereiche der Kunst, die versuchen genau die Mittel, die KIs bieten, für ihre Kunst zu nutzen
- Hier ist ein kurzes Interview mit einer Person, die eine solche Ausstellung mit iniziiert hat
Ausblick - Wie entwickelt sich das Thema aktuell weiter? (00:59:56)
- Eine Sache, die nach dem Start unserer Recherche dazu kam, ist die Sache, wie Bilder damit bearbeitet werden können
- Zum Beispiel Bilder eben bearbeiten, Katzen durch Hunde ersetzen, der Rest des Bildes bleibt aber gleich
- Auch nur Ausschnitte können dann bearbeitet werden
- Es wird ebenfalls probiert das auf anderes anzuwenden und auch Videos oder 3D-Modelle künftig generieren zu können, realistische Bewegungsabläufe von Menschen
- Links dazu: https://github.com/EricGuo5513/text-to-motion und https://dreambooth.github.io/
- Also da passiert eine Menge noch und es werden sicher noch einige Neuigkeiten auf uns zukommen
Fazit (01:01:42)
- Wir können das schon jetzt für uns nutzen: als Inspiration, für Ausmalbilder mit genau den richtigen Motiven, Rollenspieler*innen nutzen es für Szenerien, Charakterbilder etc. - und insgesamt einfach aus Spaß
- Man sollte halt Dinge wie Bias und Reproduktion von Vorurteilen im Kopf behalten, wenn man es nutzt
- Wir hatten viel spad damit das auszuprobieren und können empfehlen das auch mal zu machen
- Wir haben hier jetzt 3 Anwendungen uns näher angeguckt: Craiyon, Midjourney, stable diffusion
- Es basiert darauf, dass Rauschen erkannt und verringert wird anhand des Textes
- Gesellschaftlich gibt es ein paar diskussionswürdige punkte, wie eben genannt: datenschutz, urheberrecht und kunst
- Wir sollten uns bei Technologie immer fragen: Was wollen wir damit, was kann sie und passt das irgendwie zusammen?
Nächste Folge: Erscheint Ende November (01:04:38)
- Wir haben schon Ideen, wissen aber zum Zeitpunkt dieser Aufnahme noch nicht, wofür wir uns entscheiden
- Wie schon zu dieser Folge: Das werdet ihr dann früh genug sehen
Call to Action (01:04:58)
- Wenn ihr uns weiter hören möchtet, folgt uns auf Twitter unter @datenleben & Mastodon unter @datenleben@chaos.social
- Oder besucht unsere Webseite: www.datenleben.de
- Hinterlasst uns gerne Feedback, wir würden uns darüber sehr freuen
- Ihr könnt uns als Data Scientists auch Buchen für Analysen oder Projekte
- Habt ihr Fragen oder Themen, die euch interessieren? Dann schreibt uns!
Outro (01:05:42)
Schlagworte zur Folge
Künstliche Intelligenz, Maschinelles Lernen, Neuronale Netze, automatische Bildgenerierung
Quellen
- https://www.craiyon.com/
- Microsoft: Turing Bletchley. A universal Image-Language-Representation-Model by Microsoft
- https://www.midjourney.com/
- https://creator.nightcafe.studio/
- https://beta.dreamstudio.ai/dream
- datenleben: dl004 racial profiling
- Katrin Raabe: Kritische Gedanken zu Midjourney
- YouTube, Computerphile: How AI Image Generators Work (Stable Diffusion / Dall-E)
- https://laion.ai/blog/laion-5b/
- GitHub, CompVis: stable diffusion
- GitHub, CompVis: Stable Difussion v1 Model Card. Limitations and Bias
- https://haveibeentrained.com/
- Heise: Private Bilder aus einer Krankenakte unerlaubt als Trainings-Daten für KI verwendet
- t3n.de: Wurde mein Bild zum Training von KI-Modellen genutzt? Diese Website sagt es dir
- GitHub, EricGuo5513: Text to Motion
- https://dreambooth.github.io/
- Freesound: Sounds, die hier verwendet wurden, stehen unter CC-0